A UNICODE HASZNÁLATA A BIBLIOGRÁFIAI ADATCSERÉBEN
Horváth Ádám
horvath.adam@oszk.hu
Lakatosné Takács Rita
takacs.rita@oszk.hu
Országos Széchényi Könyvtár
1.Bevezetés
2. Kódkészletek
3. Unicode
4. Adatcsere-formátum
5. CHASE
6. A táblaszerkesztõ
program
6.1 A karakterkészlet definiálása
6.1.1 Multi-Byte
6.1.2 Diacritic Position
6.1.3 EBCDIC Character Tables
6.1.4 Character Tables
6.2 A konverzió definiálása
6.3 Karakterkonverzió
6.4 A konverziós tábla készítésének rejtelmei
6.4.1 Repülõ ékezet vagy elõre definiált karakter (combined / pre-combined)
6.4.2 Indexek
7. Bibliográfiai adatszolgáltatás
az OSZK-ban
1. Bevezetés
A bibliográfiai adatcsere formátuma valamilyen MARC formátum.
A különféle MARC kézikönyvek részletesen
szabályozzák, hogy a bibliográfiai adatokat milyen
mezõkben, hogyan kell elhelyezni. Tartalmaznak pusztán számítástechnikai
jellegû elõírásokat is, mint például
a mezõk sorrendje a MARC rekordok mutató részében.
Nem írják azonban elõ, hogy az adatokat milyen kódkészletben
kell szolgáltatni. Az alkalmazott kódkészletet a MARC
állományokat kísérõ szöveges dokumentációban
kell közölni a cserepartnerrel.
A mágneses adathordozón tárolt szövegek számítástechnikai
alapegysége az oktett. Az oktetten alapuló karaktertáblákban
maximum 256 féle karaktert lehet megkülönböztetni.
A világon elõforduló karakterek száma tízezres
nagyságrendû. A kettõ között feszülõ
ellentét különösen érzékenyen érinti
a könyvtárakat, melyek a világ minden tájáról
gyûjtik irodalmukat. Hogyan lehet ilyen körülmények
között többnyelvû szövegeket számítógéppel
kezelni? Csakis kerülõ úton. A 256-os korlát
feloldására számtalan módszer született.
Ezek egyike sem terjedt el széles körben. Ahány ház,
annyi szokás. Az adatcsere mindenképpen karakterkonverzióval
jár: annyiféle konverzióval, ahányféle
cserepartnerünk van.
1991-ben a Unicode konzorcium kiadta az Unicode szabvány elsõ
verzióját. A Unicode 16 biten ábrázolja a karaktereket.
Egy ilyen tábla több mint 65.000 karakter befogadására
alkalmas. A Unicode elterjedése megszûntethetné a mai
helyzet kuszaságát. Egy 16 bites ábrázolásra
való áttérés azonban nem egyszerû feladat.
Bíztató jelek ellenére még nagyon messze vagyunk
a Unicode általános elterjedésétõl.
A következõ fejezetekben áttekintjük a bibliográfia
adatcsere összetevõit, majd bemutatjuk a Unicode alkalmazásának
lehetõségét.
2. Kódkészletek
Az oktetten alapuló karaktertáblák között
két nagy csoport alakult ki: az ASCII és az EBCDIC. Könyvtáros
szempontból két lényeges különbség
van a kettõ között. Az ASCII táblában gyakorlatilag
csak 32 vezérlõ karakter van, míg az EBCDIC-ben 64,
ennek megfelelõen az ASCII-ban több hely marad a tényleges
karakterek számára. Ezen kívül az ASCII táblában
a számok megelõzik a betûket, az EBCDIC-ben pedig fordítva.
A könyvtári besorolás szempontjából az
ASCII megoldása kedvezõbb.
Még mindig az oktett keretei között maradva vannak
ún. gyártói szabványok, melyeket széles
körben való elterjedtségük miatt tekinthetünk
szabványnak. Az IBM kidolgozta a PC DOS operációs
rendszer számára a nemzeti karaktertáblákat.
Ezek segítségével elérhetõ, hogy az
egyes nemzetek saját nemzeti karaktereiket láthatják
viszont a képernyõn. Egy-egy "nemzeti" karaktertábla
több nemzetet szolgál. Így például a számunkra
kitalált 852-es tábla a magyar mellett a cseh és a
szlovák karakterek is tartalmazza. De természetesen egy tábla
nem szolgálhatja az összes európai nemzetet, ezért
aztán a mi kódtáblánkba nem fértek bele
például a francia karakterek. A PC DOS-os, tehát ASCII
nemzeti tábláknak megvannak a megfelelõi EBCDIC-ben
is. Az OSZK például a 870-es EBCDIC táblát
használja alap karaktertáblaként.
Az oktett határait kitágító módszerek
némelyike nemzetközi vagy nemzeti szabvány szintjére
is emelkedett. Ilyen például az ISO 2022-es szabvány,
melynek magyar megfelelõje a "Számítástechnikai
kódrendszerek: Kódkiterjesztés" címet
viseli. Ez a szabvány leírja, hogy hogyan lehet 7 és
8 bites környezetben az alap karaktertáblát a felhasználó
által tervezett táblákkal lecserélni, ill.
az alap és a felhasználói táblák között
szabadon mozogni. A módszer segítségével elvileg
korlátlan számú tábla között lehet
váltani. Tiszta megvalósítása alig ismert.
A kódkiterjesztés elterjedt módszere a karaktersorozatok
használata. NIIF körökben jól ismert az ún.
gizmós ábrázolás. Az alap karaktertáblába
nem tartozó karaktereket három karakteren fejezzük ki.
A @ jelzi, hogy most valami speciálisan értelmezendõ
karakterek következnek. A @ karakter utáni két karakter
együttesen reprezentálja az alap táblából
hiányzó karaktert. Elvileg így nagyon sok karaktert
kifejezhetünk. A gizmós karaktereket tartalmazó szöveg
nehezen olvasható. A gizmós ábrázolást
megengedõ programok általában úgy viselkednek,
hogy a gizmót és az azt követõ karaktert kérésre
nem jeleníti meg a szöveg kiírásakor. Az így
megmaradó karakter utalni szokott arra a karakterre, melyet a gizmós
ábrázolás részeként kifejez. Ezzel a
megkötéssel a variációk száma már
lecsökken. (Itt jegyezzük meg, hogy az OSZK-ban használt
DOBIS/LIBIS belsõ karakterábrázolása is ennek
a kódolási típusnak egyfajta, bonyolultabb változata.)
Ugyancsak elterjedt módszer a repülõ ékezetek
használata. Ebben az esetben olyan karaktertáblát
terveznek, mely tartalmazza az alapkaraktereket és a leggyakrabban
használt ékezeteket. Az ékezetes karaktereket aztán
két oktetten ábrázolják. Elõször
jön az ékezet, majd az alapbetû. A megfelelõen
felkészített programok az így rögzített
szövegek megjelenítésekor a kettõt egymásra
nyomtatják. Ezzel a módszerrel sem lehet mindent megoldani,
mert az összes alapkaraktert és az összes ékezetet
nem lehet egy táblázatban felsorolni.
A könyvtári szoftverek világában nem terjedt
el egyik módszer sem kizárólagosan. Sõt ennél
is rosszabb a helyzet: ahány szoftver annyiféle kódkiterjesztés.
Ha csak Magyarországra szûkítjük le a kérdést,
akkor azt láthatjuk, hogy a hazánkban elterjedt integrált
rendszerek szinte mindegyike más módszert használ.
Ráadásul a módszerek általában olyanok,
hogy a kódkiterjesztés tábláit maguknak a felhasználóknak
kell elkészíteniük. Így még az azonos
módon dolgozó szoftverek konkrét alkalmazásai
is más és más tartalmú táblákat
használnak. Egy-egy konkrét alkalmazáson belül
maradva nincs is különösebb baj: a szoftverek ha különbözõ
módokon is, de általában jól, a felhasználó
megelégedésre oldják meg az extra karakterek tárolását
és kezelését. A baj akkor kezdõdik, amikor
az adatokat ki kell cserélni, mivel nincs két rendszer, mely
ugyanazt a kódkészletet használná.
3. Unicode
A Unicode elsõ verzióját az amerikai Unicode konzorcium
készítette el és adta ki "The Unicode Standard:
Worldwide Character Encoding, Version 1.0" címmel. A kidolgozásban
többek között a Research Library Group, a Microsoft, az
IBM, a Novell, Sun Microsystem, a WordPerfect, a Xerox szakemberei vettek
részt. A szabványt nevezik UCS–2-nek (Universial Character
Set – 2 byte) is. A Unicode szabvány részhalmaza az ISO által
10646-nak nevezett szabványtervezetnek, mely 32 biten kódolja
a karaktereket. Ez utóbbit nevezik UCS–4-nek is.
A Unicode egy 16 bites fix hosszúságú kódokat
tartalmazó szabvány. Jelenleg 28.000 karaktert tartalmaz
a maximálisan kiadható több mint 65.000-bõl.
A teljes kódtartomány a karakterek ábrázolására
van fenntartva. A szabvány ugyanakkor kompatibilitási okokból
tartalmazza a legelterjedtebb szabványokban leírt karaktereket
és vezérlõ kódokat.
Az ékezetes karaktereket megtaláljuk a Unicode-ban statikus,
elõre definiált formában, ha azok elõfordultak
a fent említett szabványok valamelyikében. Pl. az
elõre elkészített Á betû Unicode-ja
U+00C11
. A Unicode szabvány felsorolja az összes ékezetet,
melyek segítségével bármelyik ékezetes
karakter elõállítható. Az ékezetek az
alapkarakter után következnek. Ez a repülõ ékezetes
módszer. Az Á repülõ ékezetes kódja:
U+0041 + U+0301, ahol U+0041 az A betû
kódja, a U+0301 a ferde ékezeté (acute).
Egy alapkarakterre több ékezet is feltehetõ. A Unicode
bevezetése nem egyszerû feladat. Az adatbázisok nagyságát
rögtön megkétszerezi, nem állnak maradéktalanul
rendelkezésre a megjelenítéshez szükséges
betûkészletek és nem megoldott a Unicode karakterek
bevitele sem, hogy csak a legnyilvánvalóbb nehézségeket
említsük. A Unicode-ra épülõ alkalmazások
száma a szabvány megjelenését követõ
tétova évek után egyre erõteljesebben növekszik.
A Microsoft operációs rendszerekben régóta
jelen van, igaz a felhasználó elõl elrejtve. A Novell
is Unicode-ot használ a fájlnevek tárolására.
A programnyelvekben egyre több Unicode-ot kezelõ rutin jelenik
meg. Piacra kerültek az elsõ Unicode-os szövegszerkesztõk,
mint például a WinCalis. Az Interneten az UTF–8 kódolás
kezd terjedni, mely a Unicode szabvány megvalósítása
változó hosszúságú kódokkal.
A Unicode-os WWW böngészõk is az UTF–8 kódolást
tudják kezelni.
Könyvtári szoftverek készítõi kezdetben
azon az állásponton voltak, hogy a Unicode kezelése
az operációs rendszer feladata, és az alkalmazói
szoftverbe csak ezután kerülhet be. Tipikus helyzet: mindenki
a másiktól várja az elsõ lépés
megtételét. Mára azonban módosulni látszanak
a vélemények és egyre több cégrõl
hallani, hogy tervezik a Unicode bevezetését saját
hatáskörükön belül. Hiába létezik
tehát a Unicode, könyvtári megjelenésére
még mindenképp várnunk kell egy-két évet.
4. Adatcsere-formátum
Minden MARC formátum – jelen esetben a bibliográfiai
adatcsere formátumot értve MARC alatt – összetevõi:
rekordszerkezet, a tartalomjelölõk és maga az adattartalom.
Megegyezés csak a rekordszerkezetben történt, az
ISO 2709-et ("Format for bibliographic information interchange
on magnetic tape") szabványként fogadták
el az adatrekordok szerkezetére vonatkozóan. Ezt a szabványt
a Magyar Szabványügyi Hivatal is honosította: "MSZ
193/1-83 Mágnesszalagos bibliográfiai adatcsere formátuma.
A rekordok szerkezete" címen.
Egy ISO 2709-es szerkezetû rekord három fõ részbõl
áll: rekordfejbõl, a mutatóból és az
adatmezõkbõl. A rekordfejben a mutató rész
felépítésére vonatkozóan is szerepel
információ. A mutató részben van leírva,
hogy a rekord adatmezõk részében milyen hívójelû
mezõk milyen hosszan és hol találhatóak. Maguk
az adatok az adatmezõk részben foglalnak helyet. Az ISO 2709
nem, de mind a USMARC, mind a UNIMARC és természetesen a
HUNMARC is elõírja, hogy a mutató részben az
adatmezõket hívójelük növekvõ sorrendjében
kell felsorolni. Az adatrészben a mezõknek nem kell ebben
a sorrendben következniük, hiszen a rekordon belüli helyüket
a mutató részbõl egyértelmûen meg lehet
határozni.
Sem az ISO 2709 szabvány, sem a MARC kézikönyvek
– mint a bevezetõben már volt róla szó – nem
írják elõ az alkalmazandó karakterkészletet.
5. CHASE
A CHASE egy általános célú karakterkonvertáló
program. Jellegzetessége, hogy képes oktettes karaktereket
Unicode-ra konvertálni. Az oktettes karakterkészlet lehet
ASCII és EBCDIC és ezeken belül:
– ISO 2022-es szerkezetû,
– repülõ ékezetes,
– karaktersorozatos kódkiterjesztést tartalmazó.
A Unicode-os ékezetes karakterek lehetnek elõre definiált
típusúak és repülõ ékezetesek.
A CHASE szoftverrel sima szövegfájlokat és ISO 2709-es
fájlokat is lehet konvertálni. Ez utóbbi esetben a
CHASE a rekordfejet is, a mutatót is Unicode-osítja és
a mutatóban a kezdõpozíciókat és hosszakat
is átszámolja az adatmezõk konverziója eredményének
megfelelõen.
Az oda-vissza konverzió egy konverziós tábla alapján
történik. A konverziós tábla készítését
külön program segíti. A CHASE program DOS alatt fut, de
már készül a UNIX-os verziója. A táblaszerkesztõ
Windows-os program. A konverziós tábla maga – amit a táblaszerkesztõ
létrehoz – egy egyszerû szövegfájl, melyet bármilyen
szövegszerkesztõbe be lehet olvasni.
A CHASE az Európai Unió COBRA kutatási programjának
keretében készült. A CHASE mozaikszó, melynek
feloldása: Character Set for Europe. A szoftver
tesztelésében az OSZK is részt vett.
6. A táblaszerkesztõ
program
6.1 A karakterkészlet definiálása
A táblaszerkesztõ program segítségével
tudjuk definiálni a konverzió input és output oldalának
jellegzetességeit. Maga a tábla ezért két,
egymástól jól elkülönülõ részre
osztható, amelyek egymás alatt helyezkednek el. A CHASE egy
általános konvertáló program, mely egyaránt
képes egy bájtos2
valamint egy és több bájtos kódkészletek
között konvertálni, ezért mindkét táblarészt
külön-külön ki kell tölteni.
Elõször is meg kell neveznünk a konvertálásban
résztvevõ kódkészleteket, vagyis ki kell töltenünk
a "Description" mezõt, melybe a konvertálandó
karakterkészlet megnevezésére szolgáló
szöveges információ kerül (1. ábra). Miután
megneveztük a konverzióban résztvevõ karakterkészleteket,
ezek jellemzése a következõ mezõk kitöltésével
történik:
– "Multi-Byte",
– "Diacritic Position",
– "EBCDIC Character Tables",
– "Character Tables".
6.1.1 Multi-Byte
A "No" kijelölésével jelezzük,
hogy a definiálandó karakterkészlet egy bájtos.
Amennyiben két bájtos karakterkészletet szeretnénk
definiálni a "High Low" vagy pedig a "Low
High" gombokat kell kiválasztanunk, ezzel jelezve a bájtok
tárolási sorrendjét.
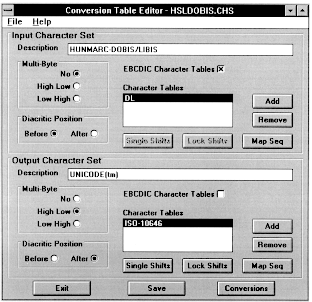
1. ábra
6.1.2 Diacritic Position
Abban az esetben, ha a definiálandó kódolás
használja a repülõ ékezetes kódkiterjesztést,
a programnak tudnia kell, hogy az ékezetek követik vagy megelõzik
az alapkaraktert. A repülõ ékezetek általában
megelõzik az alapkaraktert. A Unicode azonban szakított ezzel
a hagyománnyal és a repülõ ékezetet az
alapkarakter után helyezi el, vagyis az "After"-t
kell kiválasztanunk. A konverzió definiálásakor
adhatjuk meg, hogy mely karaktereket tekintse a program ékezeteknek.
Amennyiben a definiált karakterkészletben nincsenek repülõ
ékezetek – mint ahogyan a DOBIS/LIBIS táblában sincs
–, akkor a kijelölésnek nincs jelentõsége.
6.1.3 EBCDIC Character Tables
Amennyiben a definiálandó karakterkészlet EBCDIC
kódolású, így az ezt jelölõ négyzetet
ki kell jelölnünk.
6.1.4 Character Tables
Az Input illetve az Output karakterkészlet állhat egy
vagy – a helyi karakterkészlet sajátosságainak megfelelõen
– több táblából, melyeket a "Character
Tables" mezõben sorolunk fel. A tábla neve a konverziós
program számára szolgáló belsõ azonosító,
ezért tetszõleges elnevezéssel utalhatunk a táblára
(pl. DOBIS/LIBIS helyett csak "DL"-nek neveztük el
a táblánkat). A táblákat az "Add"
és a "Remove" gombokkal lehet hozzáadni,
illetve eltávolítani a mezõbõl.
Az ISO 2022-es szabvány esetén a "Single Shift"
és a "Lock Shift" gombokkal hozzá lehet
rendelni az egyes táblákhoz a megfelelõ egyszeres
vagy reteszelt átváltó karaktersorozatokat. EBCDIC
szabvány esetén, amennyiben karakterkészletünk
több táblából áll, az egyes táblákat
lehívó karaktersorozatokat a "Map Seq" gomb
segítségével lehet megadni. A "Map Seq"
gomb használata ASCII kódkészlet esetén is
megengedett.
Ha az output karakterkészlet Unicode, akkor a "Character
Tables" mezõben mindig egy tábla (vagyis maga a
Unicode tábla) szerepel, amelyet mi "ISO–10646"-tal
jelöltünk. A táblához természetesen nem
tartozik átváltó karaktersorozat. A "Diacritic
Position" pedig mindig "After". A bájtok
tárolási sorrendjét ("High Low" /
"Low High") a helyi operációs rendszer sajátosságainak
megfelelõen kell kiválasztani.
A konverzióban részt vevõ kódkészletek
definiálása után elmenthetjük a beállításokat,
kiléphetünk a táblaszerkesztõbõl, vagy
megkezdhetjük a konverziós tábla kitöltését.
6.2 A konverzió definiálása
A konverziót definiáló ablakban (2. ábra)
látható az elõzõekben leírt és
kiválasztott input és az output karaktertábla megnevezése.
Most már csupán a kódokat kell bevinnünk. Elõször
a kódokat írjuk be hexadecimális formában,
majd kitöltjük a "Comment" mezõt: ide
kerül a karakter szabványos megnevezése.

2. ábra
Az "Auto Increment" funkciót akkor érdemes
kiválasztanunk, ha a kódokat folyamatosan, értéküket
mindig eggyel növelve kívánjuk bevinni. Ilyenkor ugyanis
a program automatikusan az elõzõ érték után
következõ kódot ajánlja fel.
Amennyiben a helyi kódkészletben repülõ ékezetet
használunk, akkor a program számára jeleznünk
kell, hogy melyik kód az ékezet; ezt a "Diacritic"
bejelölésével tehetjük meg.
A redõnyös ablakban láthatjuk3
a korábbi bevitelek eredményeképpen létrejött
konverziós táblát, melyhez hozzáadhatjuk a
következõ karakter leírását, illetve amelybõl
törölhetjük a téves vagy feleslegessé vált
kódokat. Az így bevitt kódok összességeként
hozzuk létre azt a *.chs kiterjesztésû szövegfájlt,
melyet a konverziós program felhasznál.
6.3 Karakterkonverzió
A konverziót a CHASE program végzi. A program indítása:
"chase -st hsldobis.chs -i hsldobis.iso -o hsldobis.uni"
Mint láthatjuk parancssor argumentumokkal adhatjuk meg az input,
output és a konverziós táblát tartalmazó
fájlokat. Az "s" kapcsolóval kértük
a statisztika kiírását. Fordított irányú
konverzió esetén a hívás: "chase -sxt
hsldobis.chs -i hsldobis.uni -o hsldobis.iso".
6.4 A konverziós tábla készítésének
rejtelmei
A konverziós tábla kitöltésének általános
leírása után érdemes a felmerült problémák
közül egy-kettõt azok általunk választott
megoldását megemlítenünk, megosztva ezzel saját
tapasztalatainkat, és talán ötletet adva más,
helyi sajátosságok kezeléséhez.
6.4.1 Repülõ ékezet vagy elõre
definiált karakter (combined / pre-combined)
Mint az elõzõekben láttuk, a Unicode szabvány
szerint az ékezetes karaktereket kétféleképpen
is le lehet írni. Mi minden esetben a repülõ ékezetes
megoldást választottuk, mert ezzel a módszerrel azokat
a karaktereket is le lehet írni, melyeket a Unicode szabvány
nem sorol fel elõre definiált formában.
6.4.2 Indexek
A DOBIS/LIBIS karakterkészletében külön szerepel
a magyar ábécé valamennyi betûjének valamint
a számoknak és egyes szimbólumoknak alsó, illetve
felsõ indexként való leírása is. A Unicode
szabvány azonban ezzel a problémával tudatosan nem
foglalkozik, azt szövegszerkesztési feladatnak tekinti, így
külön kódolását sem végezte el. Vannak
ugyan kivételek: a számok valamint bizonyos szimbólumok
(melyek meglévõ szabványokban is szerepelnek) alsó
és felsõ indexe helyet kapott a Unicode táblában.
Ezek a kódok azonban nem összetettek, nem magából
a karakterbõl + az alsó vagy felsõ index jelölésére
szolgáló kódból állnak, ezért
utólagos képzésük nem lehetséges. A Unicode-ban
azonban vannak úgynevezett szabad helyek (Private Use Area), melyeket
éppen az ilyen egyéni megoldások számára
hagytak üresen; itt szabadon definiálhattuk saját, a
Unicode-ok között nem szereplõ karaktereinket. Ez a terület
a Unicode tábla E800 és FDFF kódhelyei
között találhatóak. A szabad helyek felhasználását
legalább országos szinten összehangoltan kellene végezni.
7. Bibliográfiai adatszolgáltatás
az OSZK-ban
Az OSZK a "Nemzeti Bibliográfia: Könyvek Bibliográfiája"
címû periodikum anyagát kéthetes periodicitással
HUNMARC formátumban szolgáltatja elõfizetõi
számára. A MARC rekordok a könyvtár integrált
rendszerébõl, a DOBIS/LIBIS-bõl származnak.
Jelenleg négyféle széles körben elterjedt karakterkészlettel
állítjuk elõ 4.
Közös jellemzõje mind a négy kódolásnak,
hogy a DOBIS/LIBIS belsõ karakterkészletét a legteljesebbnek
szántba sem tudjuk maradéktalanul átmenteni. A többiben
szándékosak az elhagyások: olyan rendszerek számára
készültek, melyek nem ismerik a kódkiterjesztés
módszerét.
Véleményünk és tapasztalataink szerint a
CHASE programra támaszkodva be lehetne vezetni a Unicode-os HUNMARC
adatszolgáltatást. Ezzel biztosítani lehetne, hogy
a felhasználó a DOBIS/LIBIS, vagy bármely más
adatszolgáltató saját rendszerének teljes karakterkészletét
megkapja, és ezek után maga döntsön arról,
hogy abból mit vesz át abban az esetben, ha nincs szüksége
a teljes készletre, hiszen a Unicode-ról a helyi készletre
való konverzió a felhasználás helyszínén
történne.
Amennyiben el tudnánk érni, hogy a hazai bibliográfiai
adatcsere mindig Unicode-ban történjen, akkor az összes
magyar könyvtárnak ebben a vonatkozásban csak egy konverziós
táblával kellene rendelkeznie: a helyi karakterkészletrõl
Unicode-ra és Unicode-ról a helyi karakterkészletre
konvertáló egyetlen táblára.
Ennek az a feltétele, hogy a CHASE-t teszteljük. Nem tudjuk
ugyanis, hogy az egyes magyarországi könyvtári rendszerek
milyen belsõ kódkészlettel dolgoznak, nem tudjuk,
hogy a CHASE melyeket lesz képes konvertálni, melyeket nem.
Ezért a CHASE fejlesztõinek engedélyével egy
hazai konverziós tesztet szeretnénk beindítani, tisztázandó,
hogy a Unicode ilyenmódú széleskörû hazai
felhasználása lehetséges-e? Ehhez kérjük
a könyvtárak segítségét – amennyiben fantáziát
látnak ebben az ötletben.
Jegyzetek:
1 A Unicode karakterekre a szabványos
hivatkozás a következõ: U + a Unicode karakter
hexadecimális megfelelõje.
2 A késõbb következõ
angol nyelvû ábrákhoz jobban illik a bájt szó.
Ezért ettõl a fejezettõl az oktettrõl áttérünk
a bájt megnevezésre.
3 Az ábrán éppen
karaktersorozat - Unicode definiálása látható.
4 A Nemzeti Bibliográfia füzeteit
ASCII+ (közismertebb nevén: OCLC karakterkészlet), 852+
(a 852-es kódtáblára alapozott gizmós karakterkészlet),
ISO 8859/1, ISO 8859/2 karakterkészletekben szolgáltatjuk.