A Sun Grid Engine rendszer mûködése
Stefán Péter
tudományos segédmunkatárs
NIIFI
1132 Budapest, Victor Hugo 18-22,
Phone: +36 30 3836265, e-mail: stefan@iif.hu
1. Bevezetés: interaktív, illetve kötegelt felhasználás
A korszerû, idõosztásos ütemezési elven mûködõ számítógépek lehetõvé teszik azt, hogy egyetlen processzoron több programot is lehessen futtatni, kvázi egyidõben, úgy, hogy minden egyes programot emberi mértékkel mérve rövid ideig (néhány tized-, századmásodpercig) hagyunk futni, majd környezetét, futására jellemzõ paramétereit lementjük, és egy másik programnak engedjük át a processzor használati jogát. Ily módon egymással virtuálisan párhuzamosan futó programkódok, úgynevezett folyamatok jönnek létre, melyek például a UNIX operációs rendszerben önállóan kezelhetõ és kezelendõ entitások. Az egyes folyamatok processzorhoz jutásáról az ütemezõ gondoskodik.
Amikor egy UNIX folyamatot parancsértelmezõ segítségével elindítunk, akkor egy új folyamat keletkezik (új bejegyzés a folyamatokat nyilvántartó táblába), mely egy újabb ütemezendõ elem. Az új folyamat az ütemezési stratégiának megfelelõen elõbb vagy utóbb processzorhoz is jut.
Amennyiben a folyamatba annak futása során beavatkoznak (például a program a felhasználótól vár input-ot), akkor interaktív használatról beszélünk, amennyiben ez a beavatkozás nem lehetséges, vagy a felhasználó lemond a beavatkozás jogáról, úgy a folyamat kötegelt.
Interaktív felhasználás esetén a folyamat szabványos bemenete állandóan nyitva van és rendszerint egy terminálvonal-eszközön keresztül csatlakozik a felhasználó parancsértelmezõ folyamatához. Az interaktív felhasználás jellegzetessége, hogy általában emberi mértékkel mérve rövid futási idejû alkalmazásokra használják, vagy olyan alkalmazásokra, amelyek tartósan emberi beavatkozást igényelnek. Jellemzõ rájuk a gyakori rendszerszintû input/output (IO) mûvelet, a magas prioritás, viszonylag alacsony CPU-idõ felhasználás, illetve a viszonylag intenzív folyamat kontextus váltás. A folyamat kontextus váltás költséges dolog, hiszen számos státusz-információt kell elmenteni, számos a végrehajtás felgyorsítására alkalmazott ideiglenes memóriát kell kiüríteni, stb.
Különösen nagy számításigényû, emberi mértékkel mérve nagy futási idejû (több órás, több napot átölelõ) alkalmazások esetén ez megnövelheti a programfutás technikai lebonyolításából eredõ ráfordításokat. Ilyen alkalmazások esetében sokkal "takarékosabb" az a stratégia, hogy az alkalmazás futását, ha lehet ne, vagy csak ritkán szakítsuk meg a processzor elvétele miatt, hagyjuk azokat minél tovább, esetleg a futásának befejezõdéséig egy processzoron futni. E megközelítés már a kötegelt felhasználás világába kalauzol, ahol rendszerint beavatkozás csak a program indításánál történik; ekkor biztosítjuk a szükséges inputokat), majd a program hosszabb idõn át „magára hagyva” végzi a dolgát. A kötegelt alkalmazásokra a viszonylag ritka rendszerszintû IO mûvelet, viszonylag ritka kontextus váltás és a processzor-idõszeletek teljes kihasználása jellemzi.
Szükség van tehát egy olyan eszközre, amely az operációs rendszerrel együttmûködve biztosítani tudja mind a kötegelt, mind az interaktív felhasználás lehetõségét is.
2. A Sun Grid Engine ütemezõ rendszer használatának elõnyei
A Sun Grid Engine (SGE) egy ingyenesen hozzáférhetõ erõforrás manager. Eredetileg CODINE néven, kereskedelmi szoftverként volt ismert, de 2001. júliusától forráskódja ingyenesen hozzáférhetõ a http://gridengine.sunsource.net címen.
A SGE rendszer feladata nem a párhuzamosítás, hanem egy számítógépes cluster1 erõforrásainak nyilvántartása, a cluster-be beérkezõ feladatok (jobs) nyilvántartása, és a kettõ megfelelõ feltételekkel való összerendelése. A SGE tehát egy keretprogramot ad annak érdekében, hogy a számítógépes cluster-t a lehetõ leghatékonyabb módon tudjunk felhasználni.
Miért is van erre szükség? A kérdésre a válasz többrétû gondolati kísérleten keresztül szemléltethetõ.
Egy cluster akkor mûködhet hatékonyan, ha feldolgozó egységei (számítógépei, vagy a továbbiakban csak csomópontjai) közel egyenletesen terheltek. Sajnos az algoritmusok párhuzamosítására szolgáló eszközök kevésbé a terhelés-kiegyenlítésére, mint inkább a párhuzamosítás szabványosságára, hatékonyságára koncentrálnak. Így, még az alapvetõ terheléskiegyenlítést végzõ programok, mint például a SUN HPC Cluster Tools, is túl durván, feladatszinten ütemeznek. Egyenlõ terhelésre nemcsak a relatíve kisebb teljesítményû, de nagy számú csomópontokból álló cluster-eknek van szüksége, hanem nagyobb szuperszámítógépekbõl álló cluster-eknek is! Az 1. ábra szemelvény az NIIFI Szuperszámítógép Központ két E10k gépének CPU terheltségi adataiból. Jól látható, hogy míg az egyik gép CPU kapacitásának 100%-áig terhelve van, addig a másik, idõbeli átlagot tekintve csak 50%-ban.
Gyakori rendszeradminisztrátori tapasztalat az, hogy a felhasználók szeretik programjaikat egyszerû módon futtatni. Ez a gyakorlatban annyit jelent, hogy írnak egy script-et, amelyik elvégzi helyettük az input-ok betöltését, átirányítja, átfésüli és „tálalható formába” hozza a kimeneteket. Ezt a script-et a felhasználók aztán parancssorból, vagy háttérben, vagy elõtérben futtatják. Mi ezzel a probléma? Az, hogy egy elindított program rendszerint így nincs sehol regisztrálva, mint elindított job! Tegyük fel, hogy az egyik csomópontot, például azt, amelyiken egy elindított alkalmazás egy része fut, újra kell indítani. Ebben az esetben, a futó job-ok megszûnnek, és a csomópont újraindítása után semmi sem gondoskodik ezeknek a feladatoknak az újraindításáról! Tehát nem is indulnak újra, és ha a felhasználó csak két hét múlva ellenõrzi a programját (illetve annak eredményeit), akkor ez számára két elvesztegetett hetet jelent. Ha a programot job-kezelõ környezetben indítjuk, akkor az egy lehetséges csomópont újraindítás esetén automatikusan elindul, ráadásul, ha valamiféle checkpoint2 környezetet is felhasznál, akkor minimális számítási veszeséggel3 automatikusan indul újra.
1. ábra: A felsõ diagrammon a cluster nagyobbik, 64 processzoros csomópontjának, míg az alsó diagrammon a kisebbik, jelenleg 32-processzoros csomópontjának CPU kihasználtsága látható az idõ függvényében.
Amennyiben a feladatok végrehajtása nem koordinált, még a legnagyobb számítógépekkel is gyakran elõfordul, hogy túlterhelik. Ekkor megnövekszik a load értéke, egy feladat relatíve kevesebb eséllyel jut CPU-hoz. E túlterhelt eset kezelésére számos ütemezési algoritmus létezik, például részesedésen alapuló ütemezés, amely túlterhelt állapotban megpróbálja az erõforrásokat valamilyen arányban felosztani a felhasználók között. Ez a kényszerû lépés azonban nem szerencsés. Képzeljünk el egy csomópontot 16 processzorral, két felhasználóval, akik közül az egyik 10, a másik 16 folyamatból álló feladatot futtat. Ebben a szituációban az erõforrás-ütemezõ felosztja a CPU erõforrásokat például fele-fele arányban. Ez azt jelenti, hogy mindkét felhasználó „kap 8-8 CPU-t”. Mi történik, ha a feladatok folyamatai szinkronizálni kívánnak (például barrier, vagy kölcsönös adatcsere mûveletek)? Ebben az esetben a szinkronizációs algoritmusnak megfelelõen bizonyos folyamatok szinkronizáló információt küldenek, míg más folyamatok erre várakoznak. Semmi nem garantálja azt, hogy a küldõ folyamatok (amelyek azonban majd a szinkronizáló nyugtára várakoznak), elõbb jutnak CPU-hoz, mint a várakozó folyamatok. Járulékos CPU idõkvantumok kellenek tehát a szinkronizáció lebonyolításához. Azaz a szinkronizáció teljes idõszükséglete megnõ. Ez a gyakorlatból is jól ismert jelenség: a túlterhelt számítógépen a párhuzamos alkalmazások (MPI, PVM) rosszul skálázhatók. Erre az egyedüli megoldás az, hogy nem szabad az operációs rendszer ütemezõjét túlterhelni, tehermentesíteni kell azt a nagy számítási igényû feladatok közvetlen futtatásának elkerülésével. (Ezt az erõforrások idõbeli alapon történõ particionálásának is nevezzük.)
A SGE rendszer az elõbbi problémák mindegyikére megoldást ad, ezentúl kényelmes módon lehetõvé teszi a feladatok heterogén környezetben való futtatását is!
3. A SGE építõkövei, mûködése
Az alábbiakban néhány SGE specifikus fogalom magyarázata következik.
Cluster: Nagy sebességû hálózattal összekötött, valamilyen számítási célra dedikált számítógépek halmaza.
Csomópont: az elõbbi cluster egy számítógépe.
Queue: Várakozási sor, egy adott csomópont erõforrásainak összessége. E fogalom tekintetében a SGE nem követi a hagyományos queue értelmezést, miszerint a queue a cluster-nél szûkebb, de a csomópontnál tágabb fogalom. Itt egy queue mindig a csomópont része, ennélfogva szûkebb fogalom!
Várólista (pending jobs queue): Egy cluster-hez pontosan egy várakozási lista tartozik, mely a cluster összes queue-ja számára közös.
Komplex: SGE specifikus fogalom. Minden csomóponthoz, queue-hoz meghatározott default attribútumok tartoznak. Amennyiben a konfiguráció megköveteli azt, hogy nemcsak a default attribútumokat, hanem extra attribútumokat is értelmezzük, úgy definiálnunk kell ezeket; az attribútumok leírásának eszköze a komplex. Továbbá gondoskodnunk kell az attribútum értékének elõállításáról, ami lehet a már meglévõ attribútumok aritmetikai átalakítása, vagy más attribútumok mérése (load sensor koncepció).
A SGE mûködése a 2. ábrán látható.
2. ábra: A SGE mûködése.
A feladatok az ún. submit host-okon keresztül helyezhetõk a rendszerbe. Nagygépes cluster-ek esetén ez általában egy dedikált, kis teljesítményû gép, melyre a felhasználók távolról bejelentkeznek4, és amelyen feladják feladataikat. Több PC-bõl álló cluster esetén általában a számításokat végzõ host-ok egyben submit host-ok is. Fontos megjegyezni, hogy bináris állományok nem submit-álhatók, csak script-ek. Ennek az a jelentõssége, hogy kényszeríti a felhasználót arra, hogy vegye figyelembe azt a tényt, hogy a kód, lehet, más architektúrán fog elindulni, mint amelyen feladták. Miután a SGE elfogadta a feladatot, az egy cluster-szintû, közös várakozási listán foglal helyet. A várólistán a feladatok valamilyen szempont alapján sorba rendezõdnek. E szempont lehet a submit-álás idõpontja, a felhasználók közötti részesedés-megosztás (fair share), illetve prioritás. A végrehajtó csomópontokon található összes queue is szintén valamilyen szempont alapján sorba rendezõdik, ami lehet az adott queue terheltsége5, illetve annak sorszáma. Az ütemezõ meghatározott idõnként lefult, és összeveti a várólistán elhelyezett job-okat, a queue-kat, és a pillanatnyilag rendelkezésre álló erõforrásokat. Ennek megfelelõen az erõforrások lefoglalódnak, a job a megfelelõ csomóponton CPU-ra kerül.
4. SGE architektúra
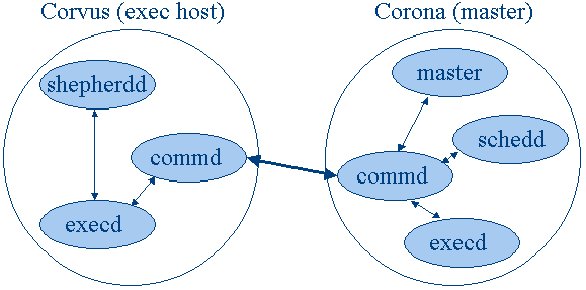
A 3. árbán az NIIFI Szuperszámítógép Központ SGE cluster felépítése látható. A cluster két csomópontból áll, corvus illetve corona elnevezéssel. Az ábrán jelölve vannak az egyes csomópontokon futó SGE démon-folyamatok is.
A commd végzi a cluster csomópontjai közötti kommunikációt, tehermentesítve a master és az ütemezõ démonokat.
A masterd démon felelõs a cluster-ben található erõforrások, job-ok, queue-k nyilvántartásáért, a belsõ adatbázis konzisztenciájának karbantartásáért.
A schedd démon végzi az ütemezést. Beállítható periodicitással meghívja az ütemezõ algoritmust. Az egy feladatnak már kiadott erõforrások alapértelmezésben nem vonhatók vissza, ellenben checkpoint környezetek alkalmazásával folyamatok futása felfüggeszthetõ, illetve újraindítható.
A végrehajtó oldalon a legfontosabb funkció a helyi erõforrások (például helyben futó feladatok, helyi paraméterek) menedzselése. E feladatot az execd démon felügyeli. Feladata minden feladat mellé egy segédfolyamatot, shepherdd-t indítani, mely egy feladat futásának teljes élettartamát végigkíséri.
5. Integráció más rendszerekkel
A SGE jelenlegi konfigurációjában számos párhuzamos könyvtárat biztosító alkalmazással együtt tud mûködni, mint például a Parallel Virtual Machine (PVM), vagy a SUN HPC Cluster Tools 4.0 Message Passing Interface (MPI) rendszere. A SGE képes az erõforrás allokációk lebonyolítására, és a megfelelõ párhuzamos szoftver vezérlésére. E szempontból a leglátványosabb megoldás a Cluster Tools 4.0 integráció.
3. ábra: Az NIIFI Szuperszámítógép Központ cluster architektúrája.
6. Felhasznált irodalom
[1] Sun Grid Engine dokumentációk http://gridengine.sunsource.net
[2] A NIIF Iroda által készített SGE dokumentációk http://www.iif.hu/szuper/sge/
[3] Különféle terhelés-kiegyenlítõ szoftverek összehasonlítása
http://www.sdsc.edu/projects/production/NQE/SysAdmin/SysAdmin_Batch.html
1 Itt a cluster fogalmán a nagy számítási kapacitásra kiélezett (High Performance Compunting), több számítógépbõl, CPU-ból, nagy memóriából, nagy diszk-kapacitásból, nagysebességû lokális hálózatból álló rendszert értjük.
2 A checkpoint fogalma azt jelenti, hogy egy alkalmazás futása felfüggeszthetõ, környezete lementhetõ, és az adott környezet birtokában újraindítható egy késõbbi idõpontban. Ha az újraindítás fizikailag egy másik gépen történik, akkor migrációról beszélünk.
3 A számítási veszteség fogalma alatt a cluster mûszaki meghibásodása miatti eredménytelen CPU-felhasználást értjük.
4 Megjegyzendõ, hogy ilyen konfiguráció esetén a számításokat végzõ, nagy teljesítményû gépekre a felhasználóknak nem feltétlen kell login jogosultságot kapniuk.
5 A beépített aritmetikai mûveletekkel egészen összetett terheltségi mutatók is definiálhatók. A gyakorlati alkalmazások döntõ többségében azonban a load/cpu_szám is kielégítõ.