
Elosztott algoritmus tervezés és modellezés PC klaszterekhez
Juhász Sándor
Budapesti Mûszaki és Gazdaságtudományi Egyetem
Villamosmérnöki és Informatikai Kar
Automatizálási és Alkalmazott Informatikai Tanszék
1111 Budapest, Goldmann György tér 3. IV. em.
E-mail: sanyo@avalon.aut.bme.hu
Kivonat
Míg a világháló szinte teljes megoldást nyújt a világméretû strukturálatlan adatmegosztásra, az e-mail rendszer az emberek közötti távoli adatcserére, addig az alkalmazások illetve a feldolgozási kapacitások hálózaton keresztüli megosztása lényegesen kiforratlanabb. Ennek legfõbb oka az egymásnak ellentmondó követelmények sokasága és az elosztott szoftver tervezés bonyolultsága. A cikkünk célja egy matematika modell bemutatása, mely lehetõvé teszi, PC klaszter környezetben futó különféle elosztott algoritmusok optimalizálását. Ennek érdekében bemutatásra kerülnek a párhuzamos algoritmusok alapfogalmai, tervezési lépései, valamint az ilyen algoritmusokkal szemben leggyakrabban támasztott követelmény rendszer.
Ha végrehajtandó feladat és a futtató környezet egyes paramétereinek ismeretében a konkrét futtatások elvégzése nélkül képesek vagyunk annak egyes tulajdonságait elõre jelezni, akkor az optimalizálási feladat egyszerû matematikai eszközökkel megoldható lesz. A cikkben bemutatott modell egy lokális hálózattal összekapcsolt, hagyományos PC-kbõl álló futtatási környezetet vesz alapul, és elsõdleges követelménynek a futási idõ minimalizálását tekinti.
A bemutatott modellezési és optimalizálási módszerek helyes mûködésének alátámasztására bemutatunk egy gyakorlati példát, melyben egy elosztott adatbázis lekérdezõ algoritmust valósítunk meg, és összehasonlítjuk a valós futtatási eredményeket az optimalizálási algoritmusból származó eredményekkel.
Designing and Modeling Distributed Algorithms for PC clusters
Abstract
While World Wide Web provides a full solution to the unstructured data sharing on the whole planet, and the e-mail systems cover all types of the remote data exchange between people, the technology of sharing of processing capacities via the network is still immature. The main reason behind this is the big number of contradictory requirements and the complexity of distributed software design. In this paper our goal is to present a mathematical model, that allows the optimization of different distributed algorithms running in a PC cluster environment. Firstly the terminology, design phases and the requirements of parallel and distributed algorithms are introduced.
The main part of this paper presents a mathematical model aiming to describe parallel algorithms in a cluster environment, built up of PCs connected with a TCP/IP network. Being able to predict certain properties of an algorithm by making some calculation based on the parameters of the system and the task to solve, the optimization can be solved with simple mathematical tools. Here the minimization of execution time is considered as primary requirement.
The demonstrate the usability of this method for modeling and optimization, an example is presented, where the measured and the predicted execution time of a distributed database query algorithm is compared.
Elosztott algoritmus tervezés és modellezés PC klaszterekhez
Az Internet kommunikációs infrastruktúrájának fejlõdésével egyre természetesebb, hogy a számítógépünk segítségével a világ bármely pontjáról könnyen és gyorsan tudunk információt szerezni. Míg a világháló szinte teljes megoldást nyújt a világméretû strukturálatlan adatmegosztásra, az e-mail rendszer az emberek közötti távoli adatcserére, addig az alkalmazások illetve a feldolgozási kapacitások hálózaton keresztüli megosztása kevésbé kiforrott.
Ennek legfõbb oka, hogy a párhuzamos és elosztott alkalmazások fejlesztése az egyszerû szekvenciális, egyetlen processzoron futó programokhoz képest lényegesen bonyolultabb, hiszen a több együttmûködõ komponens megtervezésén és elkészítésén túl meg kell szervezni ezeknek az együttmûködését is. A tervezésnek része a szoftver komponensek és a végrehajtó egységek összerendelése is. Szabványos elosztott operációs rendszerek hiányában a külön-külön törõdni kell a rendszerelemek célba juttatásának megoldásával és a kommunikációs infrastruktúra megteremtésével is. Moore törvénye alapján már több mint két évtizede érvényben van: az integrált áramkörök számítási kapacitása évente másfél-kétszeresére nõ. Mi értelme akkor a sok elemet tartalmazó, bonyolult párhuzamos rendszerek használatának? A mai áramköri technológia már a gigahertzes órajel tartományokat használja, vagyis közel járunk már a fénysebesség áthághatatlannak tûnõ korlátjához. 3*108 m/s jelterjedési sebességet feltétezve a jelzések a 30 GHz-es órajel egy periódusa alatt csupán 1 cm (3*108/3*1010 = 10-2 m) távolságra képesek eljutni, ami felülrõl korlátozza az elkészíthetõ áramkörök méretét, és ezzel a megvalósítható funkciók számát is. A fizikai korlátok áttörésének egy lehetõsége a ma is elterjedten használt párhuzamosítás.
A párhuzamosság elsõdleges célja általában a teljesítmény növelése, de a párhuzamosságban rejlõ redundanciák más (pl. biztonsági) szempontból is jól kihasználhatók, míg ezzel együtt a többszörözéssel és az elosztottsággal járó bonyodalmakat minél jobban el kell takarni. A párhuzamos rendszereknek ezért gyakran egymásnak ellentmondó feltételeket kell figyelembe vennie. A cikkünk elsõ fejezetének témája ennek a követelményrendszernek a bemutatása.
Ha sikerült a követelményeknek megfelelõ hardver és szoftver együttest találni, akkor kezdõdhet az ehhez illeszkedõ párhuzamos algoritmus megtervezése, ehhez elõször a második fejezet a párhuzamos és elosztott világhoz kapcsolódó alapfogalmakat tekinti át, majd a harmadik fejezet magával a párhuzamos algoritmus tervezéssel foglalkozik, egy általános módszertan mutatásán keresztül.
A világban számtalan párhuzamos rendszer létezik, melyek felépítése alapvetõen különbözik. A tervezésnél egyáltalán nem közömbös, hogy milyen rendszerhez kell az algoritmust illeszteni. A negyedik fejezet egy konkrét rendszer típussal a hálózati PC-kbõl felépített klaszter rendszerekkel és modellezésükkel foglalkozik. Mivel az ilyen rendszerek nagyjából homogének és földrajzilag jól behatárolhatók, egyszerûbb, jobban használható teljesítmény modell készíthetõ az algoritmus optimalizáláshoz.
A bemutatott modellek természetesen csak akkor van létjogosultsága, ha a gyakorlat is igazolja hasznosságukat. Az ötödik fejezet egy elosztott adatbázis mûvelet példáján keresztül mutatja be a modellbõl számított és gyakorlati mérések során kapott eredményeket, így demonstrálva a modell használhatóságát ennél a feladattípusnál.
Követelmények
Általános megfigyelés, hogy minden feladat tartalmaz nem párhuzamosítható, csak szekvenciálisan végrehajtható részeket. 1967-ben G. Amdahl ezt a megfigyelést így foglalta össze: ha a program csak szekvenciálisan végrehajtható része a végrehajtási idõ 1/s részét teszi ki, akkor a párhuzamos végrehajtással maximum s-szeres sebesség növekedés érhetõ el. Ha a szekvenciális rész például 10%, akkor maximum 10-szeres gyorsulás érhetõ el. A számítástechnika korai szakaszában Amdahl törvénye a párhuzamos feldolgozás általános érvényû korlátjaként vonult be a köztudatba. Bár számos esetre kétségkívül tökéletesen igaz, nem veszi figyelembe azt a tényt, hogy a párhuzamos algoritmusok alapvetõen eltérõ természetûek is lehetnek az ugyanarra a problémára megoldást nyújtó szekvenciális algoritmusnál.
Jól mutatja ezt az útépítés hétköznapi életbõl vett példája: utat lehet úgy építeni, hogy egyik végérõl elkezdve az egymást váltó különféle csoportok elvégzik a megfelelõ munkafolyamatokat, majd tovább haladnak. Mivel a technológiából adódóan minden munkafolyamat eltart valamennyi ideig és csak adott sorrendben végezhetõ, ezért a normál létszám növelésével nem érhetõ el különösebb gyorsítás. Az átadási határidõk lerövidítése érdekében az utaknak több szakaszai is egyszerre épül, így megfelelõ erõforrásokkal az építés akár annyiszor gyorsabb is lehet, ahány helyen az út egyszerre épül. Ez a második módszer azonban nyilvánvalóan drágább amiatt, hogy a munkásokat és az anyagot olyan helyre kell eljuttatni, ahova még nem vezet megépített út, azonban jobban kihasználja a munkaerõt, mivel az egyes munkafázisokat végzõ csoportoknak nem kell egymásra várni.
Az informatikában is hasonló a helyzet, a párhuzamosságtól elsõsorban nagyobb teljesítményt és jobb erõforrás kihasználást várunk. A többszálúság kihasználásával még ugyanaz a program is képes nagyobb teljesítményt nyújtani ugyanazon a processzoron, ugyanis az egyes szálaknak a szinkronizálásból, az I/O mûveletekbõl, vagy a hálózati kommunikációból adódó holtidejét a többi szál kihasználhatja. Jogos elvárás, hogy a végrehajtó egységek számának növelésével a futási idõ csökkenjen, illetve az átbocsátó képesség nõjön, vagyis több szerver több felhasználó több tranzakcióját legyen képes adott idõ alatt végrehajtani. Ehhez kapcsolódik a léptékezhetõség (skálázhatóság) igénye is, mely lényegében a teljes rendszer aktuális igényekhez igazodó átméretezhetõségét jelenti.
A fentiek megvalósítása természetesen komoly erõfeszítést igényel az elosztott alkalmazás fejlesztésénél, hiszen az elosztás megszervezése fordított erõforrások (adminisztrációs adatgyûjtés, döntési mechanizmusok, extra kommunikáció az alkalmazásban) erõsen befolyásolhatják a párhuzamosságból adódó nyereséget. A párhuzamos rendszerek megépítése ezért általában nem elegendõ, csak egy megfelelõ az operációs rendszerrel együtt válnak használhatóvá. Az amúgy sem egyszerû alkalmazásfejlesztéshez minden támogatás fontos, ezek közül talán a két legfontosabb az egységes rendszerkép (hely és gépfüggetlenség biztosítása), és a biztonsági rendszer (autentikáció, hozzáférés szabályozás, adatbiztonság) megteremtése.
A biztonsági kérdések közül érdemes külön kiemelni a hibatûrést. A párhuzamos illetve elosztott rendszerek sok elemet tartalmaznak, így nagyobb a valószínûsége a rendszeren belüli meghibásodásnak. Természetesen egy nagy komplex rendszer teljes leállását mindenképpen igyekezni kell elkerülni, sõt elõfordulhat, hogy a meghibásodott komponens szerepét egy másiknak kell átvennie. Az esetleges hiba javítás vagy bõvítés mûködés közbeni elvégzését az átkonfigurálhatóság biztosítja.
A fenti általános követelmény rendszerbõl szinte azonnal kitûnik, hogy a fenti követelmények nincsenek összhangban, számos ellentmondást található bennük (pl. a teljesítményt az összes további tulajdonság megvalósítása rontja). A párhuzamos algoritmustervezés célja, hogy a fenti követelmények között az esetenként is eltérõ optimális egyensúlyt megtalálja.
Alapfogalmak
A párhuzamos algoritmusokhoz kapcsolódó tervezési módszerek áttekintése elõtt definiáljuk a párhuzamosság fogalmát. Egy algoritmust párhuzamosnak tekintünk akkor, ha az eredményét több feldolgozó egység egyidejû, összehangolt mûködtetésének segítségével állítja elõ. A párhuzamosság számos szinten megvalósulhat, egy kombinációs hálózat kapui, egy integrált áramkör különbözõ csatornákat feldolgozó jelfeldolgozó egységei, vagy egy sok végpontos telekommunikációs rendszer elemei is mûködhetnek azonos idõben, egymástól függetlenül.
A párhuzamossággal gyakran összekapcsolódik az elosztottság fogalma is. Egy rendszer elosztott, ha a felépítésében résztvevõ végrehajtó egységek egymástól földrajzi értelemben elkülönültek, szétválaszthatók. Ez lehet külön terem, épület vagy ország is, de általában a minimum feltétel az, hogy a rendszer egyenrangú elemei legalább külön dobozba legyenek beszerelve. A fenti definíció értelmében nem tekintjük elosztottnak a chip vagy kártya szintû párhuzamosságokat tartalmazó rendszereket, viszont a több számítógépet magukba foglaló informatikai rendszerek viszont már elosztottnak számítanak. Az elosztottság nem feltétlenül jelent párhuzamosságot is, hiszen például a szinkron mûködésû kliens-szerver rendszereknél a kliens megvárja a szerverhez küldött kérések eredményeit, így a párhuzamosság alapvetõ feltétele, az egyidejû mûködés itt hiányzik.
Minden rendszer vizsgálatához szükség van egyfajta formalizmusra, mely lehetõvé teszi, az elõforduló fogalmak egységes értelmezését. A cikkben használt fontosabb fogalmak a következõképpen értendõk:
Probléma méret: a feladat során feldolgozandó adategységek száma. Az adategység a feladattól függõen lehet byte, szó vagy egy teljes adatbázis rekord is.
Végrehajtási idõ: a feladat rendszerbe jutatásának megkezdésétõl a teljes eredmény kilépéséig eltelt idõ.
Komplexitás: egy N méretû probléma komplexitása akkor és csakis akkor O(f(N)), ha létezik olyan konstans c és N0, melyekre igaz, hogyha N>N0, akkor az N méretû probléma végrehajtásának költsége kisebb vagy egyenlõ, mint c*f(N). A költség többféleképpen definiálható, lehet például a végrehajtáshoz szükséges lépésszám vagy a megoldás létrehozásának ideje is.
Alsó korlát: minden számítási problémához meghatározható egy bizonyos komplexitású algoritmus, mely a megoldásához mindenképpen szükséges, ezt alsó korlátnak nevezzük. Meghatározható például egyszerûen a ki és bemeneti mûveletek számából, vagy komolyabb matematikai megfontolások alapján is (pl. bizonyítottan N tetszõleges szám összeadása minimum O(N), sorba rendezése minimum O(N*log(N)) komplexitású) [2]. Egy algoritmus optimális, ha komplexitása a legnagyobb alsó korláttal megegyezik. Ha ilyen algoritmus még nem létezik, akkor elképzelhetõ, hogy lehet a jelenleginél jobbat találni, de az sem kizárt, hogy a legnagyobb alsó korlátot nem sikerült jól meghatározni.
Gyorsulás (speedup): a párhuzamos algoritmus minõségének meghatározásához jó módszer az ugyanazt a problémát megoldó a legjobb szekvenciális algoritmussal való összehasonlítás. A gyorsulás a két algoritmus futási idejének aránya:
Ha nem egy konkrét feladatról, hanem egy feladat típusról van szó, akkor az a worst-case eset helyett a gyorsulás az átlagos futási idõkkel is jellemezhetõ. Fontos megjegyezni, hogy az adott algoritmus végrehajtási ideje nem rögzített, hanem a feladatméret függvénye. Ez azt jelenti, hogy a gyorsulás tulajdonképpen szintén egy függvény, ezért a különféle feladatoknál az egyes problémaméret tartományokban más-más párhuzamos algoritmus bizonyulhat a legjobbnak.
Feldolgozó egységek száma: az algoritmusoknak nagyon fontos tulajdonsága, hogy mûködésükhöz hány feldolgozó egységet igényelnek. A feldolgozó egységek legalább külön processzorok, de lehet, hogy teljesen különálló számítógépekrõl van szó. Ennek a tulajdonságnak két fontos vonzata van, elsõ a költség, hiszen a számítógépek vásárlása, karbantartása és üzemeltetése pénzbe kerül, második a léptékezhetõség. Az az algoritmus, amelyik csak adott számú processzoron képes mûködni gyorsan elavul, hiszen a felmérések szerint [1] világban a processzorok száma évrõl-évre megduplázódik.
Költség: az algoritmus futtatásának költsége jól jellemezhetõ a futási idõ, és a futás során felhasznált feldolgozó egységek száma alapján:
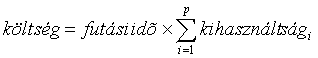
ahol p a feladat megoldásában résztvevõ feldolgozó egységek száma, és a kihasználtsági az i. feldolgozó egység átlagos terhelése a futási idõ alatt.
A költség az alsó korlátja megegyezik a legjobb szekvenciális algoritmushoz megadott alsó korláttal, mivel ellenkezõ esetben a párhuzamos algoritmus megfelelõ szekvenciálissá történõ transzformálásával egy új legjobb szekvenciális algoritmust kapnánk, ami szintén nem eshet az alsó korlát lépésszáma alá. Ennek alapján egy párhuzamos algoritmus akkor költség optimális, ha költsége az alsó korlát lépésszámának konstans-szorosa alatt marad.
Ha a párhuzamos algoritmus során végrehajtott lépések száma az alsó korláttal megegyezik, akkor annak költsége tovább már nem csökkenthetõ, azonban arra megvan a lehetõség, hogy a feldolgozó egységek számának növelésével csökkentsük a futási idõt, vagy ellenkezõleg, a futási idõ rovására csökkentsük a feldolgozó egységek számát.
Ha az alsó korlát nem ismert, akkor a párhuzamos algoritmus biztosan nem költség optimális, ha létezik nála kisebb költségû szekvenciális algoritmus.
Hatékonyság: ez a mérõszám a megoldás párhuzamos elõállításának megszervezésére fordított többletköltséget becsüli a legjobb szekvenciális és az adott párhuzamos algoritmus költségének összehasonlításával:

A hatékonyság általában ≤1, mert ellenkezõ esetben a párhuzamos algoritmusból konstruálható lenne egy minden eddiginél gyorsabb szekvenciális algoritmus. Elõfordulhat azonban, hogy a párhuzamos algoritmus gyorsasága nemcsak az algoritmusnak, hanem a feldolgozó egységek egyes tulajdonságainak is köszönhetõ (a többszörös méretû tár, illetve az egymástól független háttértárak kihasználása), ebben az esetben az egyetlen feldolgozó egységet használó szekvenciális algoritmushoz viszonyított hatékonyság akár 1-nél nagyobb is lehet.
A gyorsulás, költség és hatékonyság bevezetése lehetõvé teszi a párhuzamos algoritmusok minõségének vizsgálatát, azonban fontos megjegyezni, hogy ezek a párhuzamos algoritmusokhoz kapcsolódó paraméterek nem skalár mennyiségek, hanem a probléma méret, illetve a végrehajtó egységek számának függvényei. Ez egyben azt is jelenti, hogy nem feltétlenül található egy legjobb párhuzamos algoritmus, hanem az optimális megoldás a körülményektõl függõen eltérõ lehet.
Algoritmus tervezés
A párhuzamos algoritmusok fogalmát úgy definiáltuk, hogy olyan mûködési leírás, mely több feldolgozó egység egyidejû, összehangolt mûködtetésével állítja elõ az eredményt. Mivel az általánosan használt feldolgozó egységek alapvetõen szekvenciális programokkal vezérelhetõk, a párhuzamos algoritmus tulajdonképpen egymással kapcsolatban álló szekvenciális feladatok (taszkok) és azok együttmûködésének leírása. Az 1. ábra egy ilyen kapcsolat rendszert szemeléltet gráf formában. A gráf csomópontjait a párhuzamosan futó feladatok alkotják, és élei az információ áramlás irányát mutatják.
1. ábra. Egyszerû párhuzamos számítási modell
A párhuzamos algoritmusról alábbiakat tételezzük fel:
A párhuzamos algoritmus egy vagy több taszkból épül fel, melyek az algoritmus futása során dinamikusan keletkeznek, illetve szûnnek meg.
A taszkok a futtatandó kódból és az ahhoz rendszelt aktuális állapotából (kontextus) állnak.
A taszkok egymással üzenetek segítségével kommunikálnak. Egy taszk tetszõleges másik taszknak küldhet, illetve tetszõleges másiktól fogadhat üzenetet.
Az üzenet közvetítõ csatorna egy üzenetsor a két taszk között, az üzenet küldése aszinkron, azonnal lezajlik, az üzenetek fogadása szinkron, ami fogadó taszk által meghatározott idõben történik.
A taszkok feldolgozó egységekhez történõ hozzárendelése dinamikusan történik. Egy feldolgozó egységhez tetszõleges számú taszk hozzárendelhetõ.
Megjegyezzük, hogy másféle modellek is léteznek párhuzamos algoritmusok leírására (pl. közösen használt memóriát használó vagy adatfolyam alapú megközelítés), de mindegyiknek a lényege az, hogy a feladatot adott szempontok alapján egymással kommunikáló részekre bontsuk fel, és ezeket optimálisan a rendelkezésre álló feldolgozó egységekhez rendeljük. A párhuzamos algoritmusok tervezéséhez nehéz lépésrõl-lépésre receptet adni, mivel számos intuitív elemet tartalmaznak, de mindenképpen érdemes valamilyen módszertant alkalmazni a tervezésnél, mivel ez megkönnyíti a lehetõségek felmérését, és az alternatívák értékelését.
A legtöbb feladatnak számos párhuzamos megoldása van, és ezek közül a legjobbak általában jelentõsen különböznek a szekvenciális változat által sugallttól. Az következõkben egy olyan tervezési módszertan [1] kerül bemutatásra, mely elõször a gépfüggetlen tulajdonságokat kezeli, felderítve az algoritmusban rejlõ párhuzamosítási lehetõségeket, majd ezek után tér csak ki gépfüggõ jellemzõk meghatározására (lokalitás és egyéb teljesítménnyel kapcsolatos döntések), illetve a legvégén kerül sor a konkrét feladatok feldolgozó egységekhez rendelésére. A módszer négy lépésbõl áll, ezek a partícionálás, a kommunikáció, az agglomeráció és a hozzárendelés, a fenti lépések során végzett átalakításokat a 2. ábra szemlélteti.
A partícionálás során elsõdleges cél a megoldandó probléma felosztása kisebb egymástól független feladatok sokaságára. A felosztás kétféle alapon történhet, vagy a feldolgozandó adatok részekre osztásával, vagy a rajta dolgozó kód funkcióinak szétválasztásával. A minél finomabb felbontás érdekében célszerû a funkcionális- és az adatpartícionálást együttesen alkalmazni. Ebben a lépésben nem kell törõdni a túl finom felbontás hátrányaival, a késõbbi lépések során fognak majd kialakulni a végleges és ideális taszk méretek. A partícionálás akkor jó, ha a feladatot sikerül minél több (a feldolgozó egységek számát legalább egy nagyságrenddel meghaladó), hasonló méretû részre felosztani, olyan módon, hogy ugyanazok a mûveletek minél kevésbé ismétlõdjenek az egyes részekben. A független nem replikált mûveleteket tartalmazó részek a skálázhatóságot, a finom felbontás pedig a következõ lépések flexibilitását biztosítja.
A partícionálás során keletkezõ taszkok képesek a konkurens futásra, de egymás eredményeire is építenek. A feladatok közötti függõségek feloldására, és a lépéseik sorrendjének meghatározására a kommunikáció szolgál. A kommunikációs struktúra meghatározásánál törekedni kell arra, hogy az egyes taszkok keveset, és ha lehet csak a közvetlen szomszédaikkal kommunikáljanak. Ha egy taszk túl sok másikkal kommunikál, akkor annak funkcióit szét kell választani, illetve ha ez nem megy, mert pl. egy mindenki által használt adatszerkezetet tartalmaz, akkor a szûk keresztmetszetnek számító taszkot meg kell többszörözni. A skálázhatóság érdekében jó, ha a taszkok szabályos struktúrában (háló, fa, hiperkocka), hasonló mennyiségû adatcserét bonyolítanak.
2. ábra. A párhuzamos algoritmustervezés folyamata
Az agglomerációs fázis feladata a partícionálás során létrehozott taszkok és a köztük folyó kommunikáció granularitásának növelése. A megfelelõ taszkok összevonásával nagyobb teljesítmény érhetõ el, mivel egyrészt csökken a taszkok létrehozásával, megszüntetésével és adminisztrálásával járó többletmunka, másrészt a kommunikációs költség is lecsökken, hiszen egyes taszkközi kommunikációs lépések jóval gyorsabb belsõ kommunikációvá alakulnak. Az agglomeráció célja tehát a taszkok számának csökkentése a lokalitás elvének maximális figyelembe vételével. Míg a tervezés elsõ két lépése során nem kellett a konkrét futtató környezettel foglalkozni, addig az agglomeráció és az összerendelés a konkrét futtató környezet ismeretében kell, hogy történjen. Fontos, hogy az összevonások után legalább annyi taszk maradjon, mely az adott számú feldolgozó egység között egyenletes terhelést biztosítva szétosztható. Az agglomerációs fázisban kell mérlegelni azt is, hogy egyes számítások vagy adatok replikációjával nem növelhetõ-e még tovább a párhuzamosítás hatékonysága. A taszkok végsõ számának kialakítási módjánál figyelni kell arra is, hogy az algoritmus a skálázhatóságát megõrizze, és a hardver esetleges változása esetén ne legyen szükség a tervezési folyamat megismétlésére.
Az összerendelés feladata az agglomeráció során létrehozott taszkok futtatásának konkrét végrehajtó egységekhez való hozzárendelése. Az összerendelés végezhetõ tervezési idõben, vagy a futás közben dinamikusan is. A statikus összerendelésnek leginkább akkor van létjogosultsága, ha a taszkok felosztása adatpartícionálással történt. Ilyenkor természetes módon adódik, hogy a legnagyobb hatékonyság úgy érhetõ el, ha az agglomeráció során annyi taszkok készítünk, ahány feldolgozó egységünk van, és minden feldolgozó egységhez egyforma nagyságú, összefüggõ adattartományt rendelünk. Mivel ebben az esetben minden feldolgozó egységhez pontosan egy taszkot kell hozzárendelni, ez elõre is elvégezhetõ. Az osztott memóriát használó multiprocesszoros rendszerekben az összerendelés feladatát általában az operációs rendszer taszk ütemezõje végzi a futásra kész taszkok szabad processzorokhoz való hozzárendelésével.
Az összerendelés külön tervezést igényel elosztott többprocesszoros rendszerekben, hiszen itt a taszkok nehezen mozgathatók a feldolgozó egységek között. Az összerendelés általában két elv szerint történik, az egyik szerint a konkurensen futtatható taszkokat külön feldolgozó egységre kell helyezni, míg a másik a lokalitás növelésére törekszik az egymással gyakran kommunikáló taszkok egy helyre csoportosításával. Lényegesen megnehezíti a feladat optimális megoldását, ha taszkok számítás igénye és kommunikációs terhelése jelentõsen eltér, vagy idõben változó. Az összerendelés optimális megoldása NP teljes probléma, a minél jobb közelítõ megoldások biztosításával különféle heurisztikákon alapuló ütemezõ és terheléskiegyenlítõ algoritmusok foglalkoznak (rekurzív metszést használó módszerek, lokális minimum keresés, valószínûség számítás alapú módszerek).
A bemutatott párhuzamos tervezési lépesek látszólag egymásra építve szekvenciálisan végezhetõk, valójában azonban a tervezés lépései általában párhuzamosan zajlanak. Az egyes lépések lehetõségeinek megvizsgálása után gyakran az elõzõ lépések során kialakult eredményeket is újra át kell gondolni. A tervezési lépések eredményeinek kiértékeléséhez fontos, hogy rendelkezzünk a felhasznált futási környezet megfelelõ minõségû teljesítmény modelljével, ami lehetõvé teszi algoritmusokkal szemben támasztott, gyakran ellentmondó követelmények súlyozott kiértékelését. A következõ fejezet a PC klaszterek teljesítmény modellezését mutatja be.
PC klaszterek modellezése
Klaszter architektúra
Az elosztott informatikai rendszerek területén számos részproblémákra már kiváló megoldások születtek, a például komponensek célba juttatása (FTP, fájlmegosztás), a strukturálatlan dokumentum megosztás (WWW) vagy a személyes adatcsere (levelezõ rendszerek) már egyáltalán nem jelent problémát.
Az elosztott futtatási környezetek kialakítására is történt számos kísérlet, azonban végleges megoldások a probléma összetettsége miatt még nincsenek. A régebbi fejlesztések közül említést érdemel a PVM (Parallel Virtual Machine) és az MPI (Message Passing Interface), melyek a klaszter építésben de facto szabvánnyá is váltak. Mûködésük lényege, hogy a hagyományos programozási nyelvek kibõvítik alapvetõ kommunikációs primitívekkel és távoli gépen történõ processz kezelési lehetõségekkel. Az elosztott rendszerek egy másik megközelítése a komponens alapú szoftvertervezés, melynek két legelterjedtebb képviselõje a COM [15] és a CORBA [14].
Több nagyszabású ambiciózus projekt is létezik, mely a világ számítógépeiben rejlõ feldolgozási kapacitások egyesítését, a GRID megteremtését célozza, ezek közül talán a két legfontosabb az objektumorientált Legion [11] és az eredetileg szuperszámítógép központok összekapcsolására tervezett Globus [12] rendszer. Általános célú alkalmazások kialakítására manapság a klaszter rendszerek látszanak a legmegfelelõbbnek, hiszen viszonylag homogén felépítésük és földrajzilag jól behatárolható, kis helyen történõ elhelyezkedésük könnyen kezelhetõvé teszi õket.
A számos különféle párhuzamos számítógép architektúra létezik (közös központi memóriát használó, elosztott memóriás és vektorszámítógépek), ezek közül a klaszterek alapját az általánosított Neumann (vagy multiszámítógép) architektúra jelenti. A multiszámítógép architektúra csomópontjait önálló számítógépek képezik, melyek egy közös logikai buszra kapcsolódnak (3. ábra). A közös logikai busz lehetõvé teszi, hogy minden csomópont az összes másikat egyetlen lépésben közvetlenül elérje. A buszon ideális esetben egyszerre tetszõleges számú kommunikáció folyhat, és egy csomópont egyszerre tetszõleges számú másik számú csomópont felé továbbíthat, és tetszõleges számú másik csomópont felõl fogadhat üzeneteket.
3. ábra. Multiszámítógép, idealizált párhuzamos számítógép modell
A csomópontok lesznek az elosztott a rendszer végrehajtó egységei. Alapvetõen három fõ részbõl állnak, egy feldolgozó egységbõl (processzor), egy ehhez kapcsolódó tárból (memóriák és háttértárak) és egy kommunikációs egységbõl, mely a csomópontot a logikai buszra illeszti. Mivel a legtöbb személyi számítógép a fenti követelményeket teljesíti, sõt a kezelésükhöz szükséges operációs rendszer is rendelkezésre áll, a klaszter rendszerek felépítése lényegében a helyi operációs rendszer kiegészítése egy elosztott kommunikációt és taszkkezelést támogató réteggel. Ha ezek a számítógépek hálózatba vannak kapcsolva, a kommunikációs módszer is automatikusan adódik, a szabványos TCP/IP protokoll használata már elegendõ rugalmasságot és absztrakciót biztosít az összekapcsoló hálózat fizika tulajdonságaitól függetlenül.
Az általános multiszámítógép modellel szemben a soros elven mûködõ hálózattal összekapcsolt személyi számítógépekrõl nem mondható el, hogy tetszõleges számú, egymástól független kommunikáció folyhat a csomópontok között. Jól közelíthetõ azonban ez a tulajdonság azzal a feltételezéssel élve, hogy az üzenetek közötti ütközés viszonylag ritka. Ez olcsón elérhetõ úgy, hogy csomópontokat teljesen kapcsolt (fully-switched) hálózattal kötjük össze, és úgy választjuk meg a kommunikációs struktúrát, hogy az térben és idõben is minél egyenletesebb legyen.
Bármilyen szoftvert használunk is a klaszter egységes kialakítására, alapvetõen rétegszerkezetû virtuális gép jön létre. A rendszer integritását a klaszter felépítésében résztvevõ számítógépek operációs rendszerére épülõ új szoftver réteg, az elosztás kezelõ biztosítja. A párhuzamos algoritmust modellünkben egymással kapcsolatban álló szekvenciális feladatok (taszkok) mûködésének és együttmûködésének leírásaként definiáltuk. A klasztert taszkjai a rétegszerkezetû virtuális gép felépítésében résztvevõ számítógépek taszkjai lesznek, míg az együttmûködés lehetõségét a klaszter szoftver (middleware, elosztás kezelõ) teremti meg a 4. ábrán látható módon. Az együttmûködés alapja, hogy az egyes taszkokhoz a klaszter egészében globálisan egyedi azonosítót kell rendelni, és a már valamilyen formában azonosított taszkok között biztosítani kell az egységes, helyfüggetlen kommunikációt.
4. ábra. Klaszter rendszerek logikai felépítése
Teljesítmény modellezés
A PC klaszterben futó párhuzamos algoritmusok minden csomópontban átlapolódó feldolgozási és kommunikációs lépések sorozatából áll. A feldolgozás és a kommunikáció átlapolódását az teszi lehetõvé, hogy az egyes csomópontokban a központi feldolgozó egység (processzor) és a kommunikációs alrendszer (I/O processzor a hálózati kártyán) egymástól független mûködésre képes. Mivel az egyes feldolgozási lépések egymástól nem feltétlenül függetlenek, hiszen gyakran a megelõzõ lépések eredményeire építenek, ezért az algoritmus futási idejét a leghosszabb logikai út határozza meg. A leghosszabb út hossza a feladatot megoldó algoritmusból adódik, ennek kiszámítása megfelelõen kiegyensúlyozott szabályos struktúrák esetén általában nem jelent problémát.
A teljesítmény modellezés következõ lépése az egyes lépések végrehajtási idejének meghatározása. A feldolgozási feladatok futási idõ becslése a komplexitás meghatározásán alapul. Ha egy N méretû probléma komplexitása O(f(N)), vagyis a végrehajtásához szükséges lépésszám aszimptotikus értelemben kisebb vagy egyenlõ, mint f(N), akkor annak végrehajtási ideje felülrõl becsülhetõ az f(N) függvény felhasználásával. A végrehajtási idõt meghatározó lépések (iterációk) számának becslésére kétféle alapvetõen eltérõ számítási modell használható: egyik az elvégzett (végrehajtási idõ szempontjából) domináns mûveletek megszámlálásán alapul, míg a másik egy általános modellt (pl. polinomot, hatványsor) illeszt a mérési eredményekre. A domináns mûveletek esetenként eltérõ természetûek lehetnek: pl. egy matematikai problémánál a lebegõpontos mûveletek száma, nagymennyiségû adat feldolgozásánál a nem szomszédos tárhozzáférések (cache miss), vagy háttértárat intenzíven használó mûveleteknél a beolvasott blokkok száma. Ha már megvan a komplexitás modell, akkor az adott algoritmus különféle problémaméretekkel történõ futási idejének lemérése után a mérési eredményekbõl egyszerû (pl. regressziós) illesztéssel megkaphatók az f(N) függvény hiányzó konstans tényezõi. A matematikai módszerekkel levezetett modell elõnyt jelent, az általános közelítéssel szemben, hiszen az illeszkedés pontossága valószínûleg nagyobb lesz a lemért tartományon kívül is.
A klaszterek esetén is alkalmazható az üzenet alapú rendszerek általánosan használt [1,16] kommunikációs modellje, mely szerint az egy s méretû üzenet elküldésének ideje:
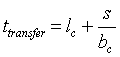 (1)
(1)
ahol lc a kommunikációs csatorna késleltetését és bc annak sávszélességét jelenti. Ha egy csatorna sávszélességét p egység közösen használja, akkor az átviteli idõ a következõképpen módosul:
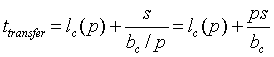 (2)
(2)
Ezek a modellek klaszter rendszerek esetén akkor alkalmazhatók, ha a kommunikációban résztvevõ csomópontok homogén kommunikációs hálózattal vannak összekapcsolva, vagyis minden csomópont kommunikációs szempontból egyenrangú. Érdemes megemlíteni, hogy a késleltetési és a sávszélesség adatok nem a fizika, hanem a logikai csatornára vonatkoznak, így a késleltetésbe az operációs rendszer és az üzenetkezelés különféle késleltetéséi (taszkváltás, üzenetsorok feldolgozási ideje) is beleszámítanak, valamint a csatorna sávszélességét nem csupán a kábelek sávszélessége, hanem a fizikai kapcsolóeszközök átbocsátó képessége és a felhasznált kommunikációs protokoll is meghatározza (adminisztrációs adatok, a nyugták küldése a hasznos adatok mellett). Mivel a késleltetéseknek egy része, pl. kapcsolat felépítéséhez szükséges üzenetváltás, függ a kommunikáló taszkok számától, az lc késleltetése is a p függvénye lesz. Ha a csatornakésleltetés konstans részét (l0) különválasztjuk, és a fennmaradó p-tõl függõ részre a (2) formulánál már használt sávszélesség megosztáson alaputó közelítést alkalmazzuk, akkor az átviteli idõ:
 (3)
(3)
ahol s0 egy virtuális üzenethossz, ami a 0 hasznos byte-ot tartalmazó üzenet p-tõl függõ késleltetésének átviteli idejét modellezi.
A klaszterek a többprocesszoros és masszívan párhuzamos rendszerektõl leginkább abban különböznek, hogy a feldolgozó egységek közötti kommunikáció nagyságrendekkel lassabb lehet az elõbbiek esetében. A klaszterekben rejlõ feldolgozási teljesítmény és lehetõ legjobb processzor idõ kihasználás érdekében az algoritmusokat úgy kell megtervezni, hogy minél jobban kihasználjuk a feldolgozás és a kommunikáció átlapolhatóságát. Ezt elõsegítheti, ha minden csomópontba több taszkot helyezünk, melyek egymás kommunikációs holtidejét kihasználva végzik a számításokat, vagy úgy is, ha a taszkokat aszinkron kommunikáció használatával úgy valósítjuk meg, hogy a háttérben küldött üzenetek ideje alatt is folyamatosan legyen munkája. Az utóbbi megoldás elõnye, hogy a túl sok taszk kezelésével járó többletadminisztrációs is elkerülhetõ.
A klaszterek esetén egyszerû feltétel adható a lassabb hálózati kommunikációból fakadó hátrányok teljes elkerülésére. A klaszter feldolgozó kapacitása akkor használható ki teljes mértékben, ha az eredeti feladat egymástól független részfeladatokra osztható úgy, hogy az azokat futtató feldolgozó egységek bemenõ adatokkal való folyamatos ellátása és az eredmények elszállítása az effektív kommunikációs sávszélesség (beff) túllépése nélkül megoldható. Az effektív sávszélesség lényegében a rendszerben található legszûkebb sávszélesség keresztmetszet jeleni, ami például egy szétosztó vagy adatgyûjtõ központ sávszélességének (a szimmetria miatt ez is bc) és az általa kiszolgált partnerek (p) hányadosát jelenti. Természeten ez a sávszélesség a növelhetõ a központosított feladat elosztás megszüntetésével, vagy hierarchikus elosztó rendszerek bevezetésével. Az effektív sávszélesség meghatározásában nem játszik szerepet a csatorna késleltetés (lc), mivel az átlapolódások, illetve az elõre beérkezõ üzenetek várakozási sorokba helyezése kompenzálja ennek hatását.
Természetesen a fenti feltételek teljes mértékben csak bizonyos feladat osztályok esetén teremthetõk meg maradéktalanul, nevezetesen azoknál, ahol a szükséges kommunikáció ideje a részfeladatok feldolgozási idejénél kisebb. Ez azt jelenti, hogy lehetõleg törekedni kell a granularitás növelésére, mivel ez az elosztás hatékonyságát elõnyösen befolyásolja, valamint az is látható, hogy effektív kommunikációs sávszélesség növelése (központi elemek eltüntetése, illetve a technológia fejlõdése) a klaszterek alkalmazhatóságát jelentõsen bõvíti.
Egyszerû adatbázis mûveltek elosztott megvalósítása
Az hagyományos hálózati PC-kbõl felépített klaszterek a jelenleg széles körben elterjedt, olcsó hálózati technológiák (pl. 100Mbit Ethernet) használata mellett is számos feladat megoldásában komoly vetélytársat jelentenek a hagyományos párhuzamos, többprocesszoros gépeknek. A különféle csupán számításigényes feladatok (kódtörés, prímszámkeresés, matematika transzformációk) mellett a kommunikáció igényesebb szimulációs feladatok (atommodell és anyagmodell számítások, töréstesztek, idõjárás elõrejelzés) is egyre inkább terjednek. Ezek általában igen számításigényes, hosszú ideig futó alkalmazások, így nagyon fontos, hogy a feladat olyan, minél kedvezõbb árú rendszeren mûködjön, mely a feladat megoldására a kívánt idõkorláton belül képes. A legfontosabb kérdések itt a következõk: Milyen futási idõre számíthatunk egy adott rendszer esetén? Legalább hány feldolgozó egységet kell összekapcsolni a kívánt teljesítmény elérése érdekében? Meddig érdemes a rendszert bõvíteni, hogy észrevehetõ teljesítmény növekedést tapasztaljunk?
Ezekre a kérdésekre a teljesítmény modellezés keresi a választ. Az elõzõ részekben bemutatott algoritmus tervezési és klaszter modellezési módszerek összekapcsolásával egy gyakorlati példán keresztül bemutatjuk, hogy a feladat és azt végrehajtó egység egyes paramétereinek elõzetes ismeretében hogyan tudjuk a végrehajtási idõket a feladat méretének és a klaszter felépítõ csomópontok számának függvényében elõre jelezni.
Párhuzamos keresés, algoritmus tervezés
Az elvégzendõ feladat legyen a következõ: adott egy n db, r méretû strukturált rekordot tartalmazó adatbázis, melybõl ki kell választani az(oka)t a rekordokat, melyeknek egy meghatározott mezõje illeszkedik egy elõre megadott mintára. A rekordok nem rendezettek, illesztést a teljes adatbázis végigolvasásával minden egyes rekordra el kell végezni (ilyen tulajdonságúak például az adatbázisokban az indexszel nem rendelkezõ mezõk).
Az algoritmus tervezés fázisai ebben az esetben meglehetõsen egyszerûek, a partícionálásnál az adat alapú felbontást célszerû alkalmazni, hiszen így minden rekord feldolgozása potenciálisan független részfeladatnak tekinthetõ. Ha ezt a feladatot egy p feldolgozó egységet tartalmazó gépen kell megoldani, akkor a kommunikáció minimalizálása érdekében érdemes a rekordokból p különálló egyforma méretû halmazt létrehozni, és ezt a halmazt egy-egy végrehajtó egységhez rendelni. Ebben az esetben a kommunikáció kialakítása p db taszk kommunikációjának megszervezését jelenti. Egyetlen kitüntetett szerepû taszk van a rendszerben, az, ahol a feladat bekerül, és ahol az eredmény is szolgáltatni kell. Az 5. ábra a feladat szétosztásának és az eredmények összegyûjtésének háromféle módját: a központosított, a hierarchikus és a gyûrûbe szervezett kommunikációs struktúrát szemlélteti.
5. ábra. a.) központosított, b.) hierarchikus, c.) gyûrûbe szervezett kommunikáció
Az adott modellek közül a legjobbat az adott feladat függvényében kell kiválasztani. A csomagkapcsolt összekapcsoló hálózat használata miatt feltételezhetjük, hogy több kommunikáció is végezhetõ egyszerre, ezért a központosított modell használata tûnik célszerûnek. Ahogy a kommunikáló taszkok száma növekszik, a központi adatelosztó csomópont szûk keresztmetszetté válhat, így a hierarchikus modellt kell alkalmazni, ilyenkor a kommunikáció ideje log p-vel arányos. A gyûrûbe szervezett kommunikáció teljesen szimmetrikus, nincsen benne szûk keresztmetszet, azonban a legutolsó csomóponthoz a feladat csak p-vel arányos idõ után jut el, és csomópontnak a részeredményeiket is csak hasonló késletetéssel képesek visszajuttatni. A fentiek miatt ezt a típust csak akkor érdemes alkalmazni, ha a rendszer folyamatosan csõvezetékszerûen mûködtethetõ, mivel ekkor az átbocsátó képességet nem befolyásolják a nagyobb késleltetések.
Jelen esetben feltételezzük, hogy a csomópontok száma elegendõen kicsi ahhoz, hogy a központosított struktúrát alkalmazzuk. Ebben az esetben az üzenetek osztoznak a központi csomópont sávszélességén a (3) formula szerint. A képletben szereplõ konstansok meghatározásáról a következõ pontban esik majd szó.
Ha minden csomópontra pontosan az adatbázis 1/p része kerül, akkor az algoritmus mûködése így a következõ lesz: a vezérlõ csomópont minden egyes dolgozó csomópontnak (beleértve saját magát is) kiosztja az illesztendõ mintát, azok megkezdik a feldolgozást, és visszaküldik az eredményt a központi csomópontnak. A fenti elrendezés kialakításával meghatározható a leghosszabb feldolgozási út, és ezzel együtt az algoritmus futási ideje is. Az algoritmus akkor fejezõdik be, amikor a legutolsó dolgozó is visszaküldte az eredményét, ha feltételezzük, hogy minden csomópont egyforma tproc idõ alatt végez a feladatával, akkor az utolsó eredményt az a csomópont szolgáltatja majd, amelyikhez a feladat legutoljára jutott el. A leghosszabb út tehát a részfeladatok kiosztásának, az utolsó feldolgozó egység futásának, és az utolsó üzenet visszaküldésének idejébõl áll össze:
![]() (4)
(4)
ahol tdist a munka teljes szétosztásához, a tproc a minta kereséséhez és a tback az utolsó eredmény visszaküldéséhez szükséges idõ. A fenti idõk a futtató környezet teljesítmény modelljébõl határozhatók meg.
Teljesítmény modellezés a párhuzamos kereséshez
Mivel a központosított kommunikációs struktúra került kiválasztásra, a kommunikációhoz kapcsolódó tdist szétosztási és a tback visszaküldési idõ meghatározásánál a (3) formulát kell alapul venni. Ebben az esetben az összes (p számú) üzenet párhuzamosan kerül kiküldésre, egyszerre ér minden címzetthez, de az átvitel mindegyik üzenethez csak a sávszélesség p-ed részét használja. Ha az illesztés feladat leírásához m byte szükséges, akkor a feladat szétosztásához szükséges tdist idõ:
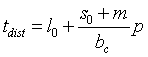 (5)
(5)
ahol l0 és s0 a kommunikációs csatorna p-tõl független illetve p-tõl függõ késleltetését modellezi, míg bc a csatorna sávszélességét jelöli. Ha a dolgozók egyszerre kezdik el a feladatot, akkor elvileg egyszerre is végeznek, mivel ugyanakkora részfeladat megoldását végzik el. Az utolsó dolgozó taszknak - és a többieknek is - tback idõre van szüksége az eredmény visszajuttatásához, ami a szétosztási idõhöz hasonlóan a csatorna l0 és s0 késleltetésétõl, bc a sávszélességétõl és az elküldött adatok mennyiségétõl függ. Ha a taszkok átlagosan x db r hosszúságú rekordot küldenek vissza, akkor az eredmények visszaküldésének ideje:
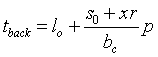 (6)
(6)
Ezek után már csak a kommunikációs csatornát leíró l0, s0 és bc konstansok értékét kell meghatározni a kommunikációs alrendszertõl független módon. Ha egyszerre csak egy kommunikáció folyik, akkor az átvitel ideje az (1) formulában leírt lc és bc mellett csak az üzenet hosszától függ. A konstansok lemérésére egyszerû program készíthetõ, melynek kliens oldala változó hosszúságú üzeneteket küld a szervernek, mely egyszerûen csak visszaküldi azt. A kliens méri az üzenet elküldése és a válasz megérkezése között eltelõ idõt (tmért), mely az adott hosszúságú üzenet átvitelének kétszerese lesz, így:
 (7)
(7)
ahol h az éppen elküldött üzenet hossza. Megfelelõ mennyiségû mérés elvégzésével a kereset konstansok az adatokból elsõfokú regresszió számítással megkaphatók.
A következõ lépés az lc késletetésnek a párhuzamosan futó üzenetnek számától (p) függõ és független részének meghatározása. Ha a mérõ kliens p szervernek párhuzamosan küld egy hasznos részt nem tartalmazó (nulla hosszúságú) üzenetet, és azok egy hasonló üzenettel válaszolnak, akkor az összes válaszüzenet kliens oldali begyûjtésének idejébõl (tmért) s0 a (3) képlet alapján a (7) formulából meghatározott bc segítségével számítható, mivel:
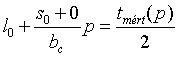 (8)
(8)
A tproc feldolgozási idõ meghatározásához szükség van egy feldolgozási modell kialakítására. Mivel a keresési mûvelet minden egyes rekordra hasonló a mintaillesztési mûveletnek az elvégzését jelenti, valószínûsíthetõ, hogy a keresés idejét leginkább egy rekordok (i) számától függõ lineáris komponens határozza meg. Minden feldolgozási mûvelet tartalmaz olyan részeket, melyeket a probléma méretétõl függetlenül kell elvégezni, példánkban ilyen például a fájl megnyitása és lezárása, melyet a konstans c0 tag modellez. A feldolgozási idõ tehát a feldolgozandó rekordok számának függvényeként egy lineáris modellel jellemezhetõ
![]() (9)
(9)
Mivel a keresésben részt vevõ n rekord a p számú feldolgozó egység között egyenletesen oszlik meg, az i helyére n/p helyettesítendõ. A c0 és c1 konstansok értékének meghatározása szintén lineáris regresszió segítségével történik, a klaszter egyik csomópontján a különféle rekordszámokhoz tartozó keresési idõ lemérése alapján. A keresés teljes futásának teljes ideje a (5), (6) és (9) alapján:
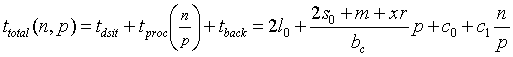 (10)
(10)
A kommunikáció és a feldolgozás modellezésére kialakított fenti módszerek feltételezik, hogy a klaszter kommunikációs és feldolgozási szempontból homogén. A módszer nagy elõnye, hogy tetszõleges feldolgozási környezetben alkalmazható, mivel a futási idõ meghatározásához szükséges mérések az adott környezet tulajdonságait is magukba foglalják (operációs rendszer és az aktív hálózati elemek kommunikációs késleltetése, a taszkok számára ténylegesen elérhetõ sávszélesség). Természetesen a kommunikációs és a feldolgozási konstansok meghatározásához szükséges méréssorozatot csak egyszer kell elvégezni, utána azok már tetszõleges számú késõbbi futtatás idejének elõrejelzésénél használhatók, akár a paraméterek, itt a rekordok és az illeszkedõ minták számának változtatása mellett is.
Mérési eredmények
A mérések során 15db, 100Mbit-es hálózattal switchen keresztül összekapcsolt 225 MHz processzorfrekvenciájú Intel Pentium számítógépet használtunk. A számítógépek egyenként 128 Mb memóriával és 600Mb kapacitású háttértárral voltak felszerelve.
A hálózati kommunikáció sebességét 0 és 32000 tartományban 12800 byte-onként mértük, és az eredményeket a 6. ábrán látható grafikonon foglaltuk össze. A mérési eredményekbõl regresszió segítségével kiszámított
lc = 0,031s és bc = 4,348 Mb/s
értékek által meghatározott közelítõ egyenest szintén feltüntettük az ábrán.
6. ábra. Hálózati kommunikáció mérése két csomópont között
A kommunikációs modellhez tartozó második, párhuzamos kommunikációhoz kapcsolódó mérés eredménye és a lineáris közelítõ egyenes a 7. ábrán látható.
7. ábra. Hálózati kommunikáció mérése a párhuzamosan küldött üzenetek számának függvényében
A regressziós egyenes adatainak (0,0175s+p*0,00548s) és az elõzõleg megkapott bc csatorna sávszélességnek a felhasználásával a (8) képlet alapján a csatornakésleltetést jellemzõ konstansok értéke:
l0 = 0,0175s és s0 = 23800 byte
A 8. ábrán az adatbázis végigkeresésének idejét tüntettük fel, 0 és 400.000 rekord között 10.000-es lépésközzel mérve. A rekordok mérete minden esetben 128 byte volt. A mérési adatokból látható, hogy a lineáris modell a vizsgált tartományban meglehetõsen pontos illeszkedést ad. A regresszió számítással meghatározandó konstansokra a következõ adódott:
c0 = 0,015 és c1= 1,05*10-5.
A 8. ábrán a mérési adatok mellett a közelítõ görbe alakulását is feltüntettük.
8. ábra. Feldolgozási sebességhez kapcsolódó mérési eredmények
8. ábra. Feldolgozási idõ a feladatméret függvényében
Az bc, l0, s0, c0 és c1 konstansok ismeretében a (10) formula alapján már tetszõleges rekordszámra és klaszter méretre elõre jelezhetõ a futási idõk alakulása.
A futtatások folyamán az illesztési feladat leírása egy m = 68 byte hosszúságú csomag szétküldésével történt meg. A minták közül mindig csak egy illeszkedett a keresési mintára (x = 1), ami egy index nélküli mezõben találtható egyedi, konkrét érték keresését szimulációjának felel meg. A rekordhossz a teljesítmény konstansok mérésénél is alkalmazott r = 128 byte volt. Ebben az esetben a futási idõ az alább függvény szerint alakul:
 (11)
(11)
A futási idõ elõrejelzést elvégeztük három különbözõ feladatméretre (n1 = 500 000, n2 = 100 000, n3 = 25 000), 1 és 15 közötti csomópont szám alkalmazásával, majd elvégeztük az adott keresési feladatok idejének tényleges lemérését is. A 9. ábrán látható az elõrejelzett és a tényleges futási idõk alakulása. Az egyes ábrák mellett található táblázatok a grafikonokon látható eredmények számszerû összehasonlítását és a predikció relatív hibáját tartalmazzák.
Az ábrák és a táblázatok jól mutatják, hogy a kialakított modell széles tartományban hûen tükrözi a klaszter valós teljesítményét. A modell képes a probléma méret több dekádos változásának követésére, és a különféle processzorszámok mellett is jól mutatja a futási eredmények várható alakulását a vizsgált mérettartományban.
a) n1 = 500 000
|
csomópontok száma [db] |
mért futási idõ [s] |
számított futási idõ [s] |
relatív hiba [mért %] |
|
1 |
19,5999 |
5,3110 |
72,9 |
|
2 |
2,7523 |
2,6970 |
2,0 |
|
3 |
1,9437 |
1,8330 |
5,7 |
|
4 |
1,6108 |
1,4065 |
12,7 |
|
5 |
1,3496 |
1,1550 |
14,4 |
|
6 |
1,1651 |
0,9910 |
14,9 |
|
7 |
1,0124 |
0,8770 |
13,4 |
|
8 |
0,9648 |
0,7942 |
17,7 |
|
9 |
0,9273 |
0,7323 |
21,0 |
|
10 |
0,9072 |
0,6850 |
24,5 |
|
11 |
0,9749 |
0,6482 |
33,5 |
|
12 |
0,9173 |
0,6194 |
32,5 |
|
13 |
0,9347 |
0,5968 |
36,2 |
|
14 |
0,8982 |
0,5789 |
35,5 |
|
15 |
0,8509 |
0,5649 |
33,6 |
b) n2 = 100 000
|
csomópontok száma [db] |
mért futási idõ [s] |
számított futási idõ [s] |
relatív hiba [mért %] |
|
1 |
1.0970 |
1.1110 |
1.3 |
|
2 |
0.6820 |
0.5970 |
12.5 |
|
3 |
0.5292 |
0.4330 |
18.2 |
|
4 |
0.4967 |
0.3565 |
28.2 |
|
5 |
0.4751 |
0.3150 |
33.7 |
|
6 |
0.4340 |
0.2910 |
33.0 |
|
7 |
0.3900 |
0.2770 |
29.0 |
|
8 |
0.3604 |
0.2692 |
25.3 |
|
9 |
0.3411 |
0.2656 |
22.1 |
|
10 |
0.3292 |
0.2650 |
19.5 |
|
11 |
0.3149 |
0.2664 |
15.4 |
|
12 |
0.3087 |
0.2694 |
12.7 |
|
13 |
0.4203 |
0.2737 |
34.9 |
|
14 |
0.5016 |
0.2789 |
44.4 |
|
15 |
0.6142 |
0.2849 |
53.6 |
c) n3 = 25 000
|
0.2786 |
0.3235 |
16.1 |
||||
|
2 |
0.2457 |
0.2032 |
28.9 |
||||
|
3 |
0.1889 |
0.1705 |
9.8 |
||||
|
4 |
0.1927 |
0.1596 |
17.2 |
||||
|
5 |
0.1836 |
0.1575 |
14.2 |
||||
|
6 |
0.1707 |
0.1597 |
6.4 |
||||
|
7 |
0.1742 |
0.1645 |
5.6 |
||||
|
8 |
0.1717 |
0.1708 |
0.5 |
||||
|
9 |
0.1697 |
0.1781 |
4.9 |
||||
|
10 |
0.1764 |
0.1862 |
5.6 |
||||
|
11 |
0.1752 |
0.1948 |
11.2 |
||||
|
12 |
0.1861 |
0.2038 |
9.5 |
||||
|
13 |
0.1902 |
0.2131 |
12.0 |
||||
|
14 |
0.5968 |
0.2227 |
62.7 |
||||
|
15 |
0.6418 |
0.2324 |
63.8 |
9. ábra. A mért és az elõrejelzett futási idõk összehasonlítása
A vizsgálatok során a modell két esetben mutatott jelentõsebb eltérést a mért adatokhoz képest. Ha az egy csomópontra esõ feldolgozandó adatmennyiség nem fér be a fájl cache-be, akkor a lineáris feldolgozási modell érvényét veszíti, és jelentõsen megnövekvõ végrehajtási idõkkel kell számolni (ez a bemutatott ábrákon csak az n1 = 500 000 rekord egy csomópontos feldolgozása esetén látható, amikor a feldolgozó egység 500 000*128 = 64 Mbyte adaton dolgozik).
Az eltérések másik típusa viszonylag kevés feldolgozandó adat és a magasabb csomópontszám esetén kerül elõtérbe. Ekkor a válaszüzenetek viszonylag és közel egyszerre érkeznek vissza, ezért a központi csomópont kommunikáció kezelõ képessége szûk keresztmetszetté válik. A lineáris kommunikációs modell ekkor csupán egy alsó becslést jelent, a tényleges válaszidõk lényegesen nagyobbak is lehetnek. Ez példánkban az n2 = 100 000 és az n3 = 25 000 esetben is látható 12 vagy több csomópont használata esetén. Ez a nagyobb klaszterek esetén fellépõ anomália elkerülhetõ, ha nem központosított, hanem egy kiegyensúlyozottabb, pl. hierarchikus vagy logikai gyûrûs kommunikációs struktúrát használunk.
Összefoglalás
A sok személyi számítógép teljesítményét egyesítõ párhuzamos feldolgozás számos probléma megoldására ígéretes lehetõségnek tûnik, mivel olcsón, nagy potenciális számítási teljesítményhez juthatunk. A rendelkezésre álló kapacitások kihasználása azonban általában nem egyszerû, hiszen a feladat szétosztása, a részfeladatok célba juttatása, a köztük fennálló függõségek feloldása, és a végeredmény elõállítása külön erõfeszítést igényel, sõt bizonyos határon túl a szervezési költségek teljesen felemészthetik a párhuzamosításból származó többlet teljesítményt.
A cikkben vizsgált, személyi számítógépekbõl felépülõ, viszonylag kisméretû klaszterek esetén szintén megjelenik ez a probléma. Az ilyen típusú párhuzamos gépekben a legnagyobb problémát a szervezéshez alapvetõen szükséges kommunikáció viszonylagos lassúsága okozza. A párhuzamos algoritmusokról általánosságban elmondható, hogy a feldolgozó egységek számának növelése nem feltétlenül jelenti a hasznos teljesítmény növekedését is, sõt, mint ez a 9. ábra c) esetében világosan látható, a túl sok csomópont a teljesítményt negatívan is befolyásolja. Ezért fontos a teljesítmény elõrejelzés, hiszen a megfelelõ paraméterek ismeretében lehetségessé válik a körülményekhez legjobban alkalmazkodó, optimális csomópontszám meghatározása.
A cikk célja egy olyan párhuzamos futtatási környezet és algoritmus modellezési technika bemutatása volt, mely lehetõvé teszi, hogy környezet és az algoritmus struktúrájának ismeretében néhány egyszerû mérés elvégzése után az algoritmus futási ideje megfelelõ pontossággal elõre jelezhetõ legyen. Láthattuk, hogy már a viszonylag egyszerû lineáris modellek is alkalmasak lehetnek a gyakorlatban is gyakran elõforduló problémák (ilyen volt adatbázis keresés példa) leírására.
A bemutatott példa jól mutatta, hogy a modellbõl számított és a gyakorlatban mért futási idõk összhangban vannak, bár egyes esetekben (pl. magasabb csomópontszám) a modell további finomítása lenne indokolt. A finomítások elvégzése azonban óhatatlanul a modell komplexitásának növekedésével jár, ami leginkább a modell használatához szükséges mérésék számában és bonyolultságában nyilvánul meg.
Érdemes megjegyezni, hogy az ilyen általános teljesítmény modellek nem csupán a futási idõ egy-egy paraméter kombináció esetén való elõrejelzését teszik lehetõvé, hanem függvény alakjukkal jól jellemzik az algoritmus és a futtatási környezet adott együttesét, így lehetõvé téve azok együttes viselkedésének különféle általános szempontokból történõ leírását is (költség, hatékonyság, gyorsulás, skálázhatóság).
Irodalomjegyzék
[1] Ian T. Foster: Designing and Building Parallel Programs, Addison-Wesley Inc., USA, 1995.
http://www.mcs.anl.gov/dbpp/
[2] Selim G. Akl: The Design and Analysis of Parallel Algorithms, Prentice Hall, Englewood Cliffs, New Jersey, USA, 1989.
[3] Barry Wilkinson, Michael Allen: Parallel programming, Prentice Hall, Upper Saddle River, New Jersey, USA, 1999.
[4] Rajkumar Buyya (editor): High Performance Cluster Computing: Architectures and Systems, Volume 1, Prentice Hall, Upper Saddle River, New Jersey, USA, 1999.
http://www.dgs.monash.edu.au/~rajkumar/cluster
[5] Rajkumar Buyya (editor): High Performance Cluster Computing: Programming and Applications, Volume 2, Prentice Hall, Upper Saddle River, New Jersey, USA, 1999.
http://www.dgs.monash.edu.au/~rajkumar/cluster
[6] Gregory F. Pfister: In Search of Clusters, Second Edition, Prentice Hall, Upper Saddle River, New Jersey, USA, 1998.
[7] Errol Simon: Distributed Information Systems, McGraw-Hill, London, UK, 1997.
[8] W. Smith, I. Foster, V. Taylor: Predicting Application Run Times Using Historical Information,
Proc. IPPS/SPDP ’98 Workshop on Job Scheduling Strategies for Parallel Processing, 1998.
[9] P. Kacsuk, G. Dózsa, F. Fadgyas: Designing parallel Programs Based On Collective Breakpoints,
Proc. Of Int Symp. on Software Engineering for Parallel and Distributed Systems, 1999, pp. 83-96
[10] Sándor Juhász, Hassan Charaf: Virtuális számítógép architektúra hálózati PC-kre, Networkshop’2001 konferencia kiadvány, Sopron, 2001.
[11] A. Grimshaw, W. Wulf, J. French, A. Weaver, and P. Reynolds, Jr., Legion: The next logical step toward a nationwide virtual computer, tech. rep. CS-94-21, Department of Computer Science, University of Virginia, 1994.
http://legion.virginia.edu/
[12] The Globus Project.
http://www.globus.org/
[13] P. Kacsuk, F. Vajda: Network based distributed computing (Meatcomputing), MTA SZTAKI, ERCI, 1999
http://www.sztaki.hu
[14] Overview of CORBA
http://www.cs.wustl.edu/~schmidt/corba-overview.htm
[15] Guy Eddon, Henry Eddon: Inside COM+ Base Services, Microsoft Press, Redmond, Washington, 1999.
http://www.hlrs.de/structure/organisation/par/projects
[16] D.R. Helman, J. JáJá. Sorting on Clusters of SMPs, 1998.
http://acs.umd.edu/research/EXPAR/papers/smpsort.ps
[17] H. Bal. Programming Distributed Systems, Prentice-Hall, London, UK, 1990.